In this post, we will implement the K-Nearest Neighbors (KNN) algorithm from scratch in Python. KNN is a simple, yet powerful non-parametric algorithm commonly used for both classification and regression tasks. Unlike many machine learning algorithms, KNN doesn’t require an explicit training phase, as it falls under the category of instance-based learning. The core assumption behind KNN is that similar data points are typically located near one another in the feature space.
For classification tasks, KNN operates by measuring the distance between the new data point and all the points in the training set. It then identifies the K closest points, and the majority class among these neighbors is used to predict the class of the new point. The proximity of each neighbor can be weighted by its distance to ensure closer neighbors have a greater influence on the prediction.
In this post, we’ll break down how to implement this intuitive and flexible algorithm from scratch in Python.
Model Formulation
In K-Nearest Neighbors (KNN) classification, a query point (i.e., the one requiring a prediction) is classified based on the majority class of its nearest neighbors in the training data. Given a query point , the classifier finds the nearest points in the training set based on a chosen distance metric.
Distance Metrics
The choice of distance metric is an important hyperparameter in KNN, as it determines how the algorithm measures the similarity between data points. The most common distance metrics include Euclidean distance and cosine similarity.
For a query point and a training point , the Euclidean distance is defined as:
where is the dimensionality of the data points. Cosine similarity measures the angle between the vectors of two points, calculated as:
The predicted label for a query point is determined by the majority vote from its -nearest neighbors. The vote can be either uniform or weighted based on the distance between the query point and its neighbors.
Note: the concept of distance and similarity is related but not identical. In KNN, we typically use distance metrics to measure the similarity between data points. The cosine similarity, which is between 0 and 1, can be converted to a distance metric by subtracting it from 1.
Decision Rule
Let denote the set of -nearest neighbors of . The predicted class is:
where is a weight applied to neighbor and is an indicator function that equals 1 if the neighbor’s class is , and 0 otherwise.
Python Implementation
Cosine Similarity
Let’s start by implementing the cosine similarity function in Python. We’ll use the numpy library for vectorized operations.
Hide Code
def custom_cosine_similarity(sample: np.ndarray, X: np.ndarray) -> np.ndarray:""" Compute the cosine similarity between a sample and all samples in a dataset. Parameters ---------- sample : np.ndarray A single sample as a row vector with dimensions (1, n_features). X : np.ndarray The training data matrix with dimensions (n_samples, n_features). Returns ------- np.ndarray The cosine similarities between the query sample and all samples in the training data matrix. """# Compute the dot products between the sample and all samples in the dataset# The result is a row vector with n_samples elements dot_products = np.dot(X, sample.T)# Compute the L2 norm of the sample and all samples in the dataset# This is a scalar value sample_norm = np.linalg.norm(sample)# The axis=1 argument ensures that the norm is computed along the feature axis# X_norm is a row vector with n_samples elements X_norm = np.linalg.norm(X, axis=1)# The broadcasting of sample_norm and X_norm is handled automatically cosine_similarities = dot_products / (sample_norm * X_norm +1e-8)return cosine_similarities
Note the use of in the np.linalg.norm() function to compute the norm along the feature axis. This ensures that the norm is calculated for each sample in the training set. By default, np.linalg.norm() computes the Frobenius norm of the entire matrix (a 2D array).
Eucledian Distance
Next, we’ll implement the Euclidean distance function in Python. Again, we compute the distances between a single sample and all samples in the training set.
Hide Code
def custom_euclidean_distances(sample: np.ndarray, X: np.ndarray) -> np.ndarray:""" Compute the Euclidean distance between a sample and all samples in a dataset. Parameters ---------- sample : np.ndarray A single sample as a row vector with dimensions (1, n_features). X : np.ndarray The training data matrix with dimensions (n_samples, n_features). Returns ------- np.ndarray The Euclidean distances between the query sample and all samples in the training data matrix. """# X is (n_samples, n_features) and sample is (1, n_features), and so the subtraction is broadcasted along the first dimension (i.e., each row of X is subtracted by sample)# The result is a matrix with dimensions (n_samples, n_features) differences = X - sample squared_differences = differences**2# Sum across the feature axis to obtain the sum of squared differences for each sample# The result is a row vector with n_samples elements squared_distances = np.sum(squared_differences, axis=1) euclidean_distances = np.sqrt(squared_distances)return euclidean_distances
Once again, we utilize broadcasting and element-wise calculations:
Subtracting the sample from all samples in the training set is broadcasted along the first dimension (i.e., the rows of ). This results in a matrix with the same dimensions as , whose rows are the element-wise differences between the sample and each training sample.
Squaring the differences is performed element-wise, resulting in a matrix with the same dimensions as .
Summing across the feature axis (axis=1) calculates the sum of squared differences for each sample in the training set, resulting in a row vector with elements.
Finally, taking the square root of each sum of squared differences yields the Euclidean distances between the query sample and all training samples.
KNN Classifier
Initialization
The initializer logic is straightforward as we only need to store the hyperparameters.
Hide Code
class KNNClassifier(BaseEstimator, ClassifierMixin):""" K-Nearest Neighbors classifier. """def__init__(self, n_neighbors: int=5, weights: str="distance", metric: str="cosine", metric_params: Optional[Dict[str, Any]] =None, ) ->None:""" Initialize the KNN classifier instance. Parameters ---------- n_neighbors : int The number of nearest neighbors to consider. weights : str The weight function to use in prediction. Possible values are 'uniform' and 'distance'. - 'uniform' : All points in each neighborhood are weighted equally. - 'distance' : Weight points by the inverse of their distance. metric : str The similarity function to use. Possible values are 'cosine' and 'euclidean'. metric_params : Optional[Dict[str, Any]] Additional keyword arguments for the metric function. See the documentation of scipy.spatial.distance and the metrics listed in distance_metrics for valid metric values. Returns ------- None """self.n_neighbors = n_neighborsself.weights = weightsself.metric = metricself.metric_params = metric_params
Fit Method
As discussed earlier, KNN is a lazy learner and doesn’t learn any model during the training phase. Instead, it stores the training data for later use. The fit() method in the KNN classifier simply stores the training data and the target labels. Some housekeeping tasks are also performed, such as validation logic (only needed if we want sklearn compatibility), encoding the target labels, and storing the unique classes seen during training.
Hide Code
def fit(self, X: Union[csr_matrix, np.ndarray, pd.DataFrame], y: Union[np.ndarray, pd.Series, MutableSequence[Union[str, float]]],) -> Self:""" The KNN classifier does not learn a model. Instead, it simply stores the training data. It is a 'lazy' learner. Parameters ---------- X : Union[csr_matrix, np.ndarray, pd.DataFrame] The input data. y : Union[np.ndarray, pd.Series, MutableSequence[Union[str, float]]] The target labels. Returns ------- Self The instance itself. """ X, y = check_X_y( X=X, y=y, accept_sparse="csr", ensure_2d=True, allow_nd=False, y_numeric=False, ) check_classification_targets(y)# Attributes that have been estimated from the data must end with a trailing underscoreself.X_train_ = Xself.label_encoder_ = LabelEncoder()self.y_train_ =self.label_encoder_.fit_transform(y)self.classes_ =self.label_encoder_.classes_ # Unique classes seen during fitself.n_features_in_ = X.shape[1] # Number of features seen during fitreturnself
Predict Method
The predict() method is where the actual prediction interface is implemented. For each query sample, the method calculates the distances to all training samples and identifies the nearest neighbors. The class label of the query sample is then determined by the majority class among the neighbors.
Hide Code
def predict(self, X: Union[csr_matrix, np.ndarray, pd.DataFrame]) -> np.ndarray:""" Predict the labels for the test set using the KNN algorithm. Parameters ---------- X : Union[csr_matrix, np.ndarray, pd.DataFrame] The input data. Returns ------- np.ndarray The predicted labels. """ check_is_fitted(self, ["X_train_", "y_train_", "label_encoder_", "classes_", "n_features_in_"], ) X = check_array(X, accept_sparse="csr")# Handle edge case: only one class in training dataiflen(self.classes_) ==1:# The classes_ attribute was already in the format before encoding, so we can return it directlyreturn np.full(shape=X.shape[0], fill_value=self.classes_[0]) predictions = np.zeros(X.shape[0], dtype=int)for i, test_sample inenumerate(tqdm(X)):# Calculate distances to all training samples test_sample_reshaped = test_sample.reshape(1, -1) distances =self._compute_distances(test_sample_reshaped)# Identify the indices of the k nearest neighbors k_indices = np.argsort(distances, axis=-1)[: self.n_neighbors]# Predict class based on nearest neighbors prediction =self._predict_from_neighbors(k_indices, distances) predictions[i] = predictionreturnself.label_encoder_.inverse_transform(predictions)
The internal methods _compute_distances() and _predict_from_neighbors() are used to calculate the distances between the query sample and all training samples, and to predict the class label based on the nearest neighbors, respectively.
Note: In this implementation, we substituded the educlidean distance and cosine similarity functions with implementations from the from sklearn.metrics.pairwise module. On the one-hand, it is useful to implement these functions from scratch to understand the underlying concepts. On the other hand, the scikit-learn implementation is optimized and more efficient, so using them directly here speeds up the runtime quite a bit.
Hide Code
def _compute_distances(self, test_sample: Union[np.ndarray, csr_matrix]) -> np.ndarray:""" Compute the distances of the test sample to all training samples. Parameters ---------- test_sample : Union[np.ndarray, csr_matrix] A single test sample. Returns ------- distances : np.ndarray Distances from the test sample to each training sample. """ metric_params = {} ifself.metric_params isNoneelseself.metric_paramsifself.metric =="cosine":return (1- cosine_similarity( X=test_sample, Y=self.X_train_, **metric_params ).flatten() )elifself.metric =="euclidean":return euclidean_distances( X=test_sample, Y=self.X_train_, **metric_params ).flatten()else:raiseNotImplementedError(f"Unsupported similarity function '{self.metric}'" )
Similarly, the _predict_from_neighbors() method calculates the class label based on the majority class among the nearest neighbors.
Hide Code
def _predict_from_neighbors(self, k_indices: np.ndarray, distances: np.ndarray) ->int:""" Predict the class of a sample based on its nearest neighbors. Parameters ---------- k_indices : np.ndarray Indices of the k nearest neighbors. distances : np.ndarray Distances from the sample to each neighbor. Returns ------- prediction : int Predicted class label. """ k_nearest_labels =self.y_train_[k_indices]ifself.weights =="distance":# Inverse distance weighting, considering a small epsilon to avoid division by zero inv_distances =1/ (distances[k_indices] +1e-8) weighted_votes = np.bincount( k_nearest_labels, weights=inv_distances, minlength=len(self.classes_) )elifself.weights =="uniform":# Uniform weights (each neighbor contributes equally) weighted_votes = np.bincount(k_nearest_labels, minlength=len(self.classes_))else:raiseValueError(f"Unsupported weight function '{self.weights}'")return np.argmax(weighted_votes)
Scikit-Learn Compatibility (Optional)
An additional feature of the implementation above is that it is compatible with the scikit-learn API. This means that the KNN classifier can be used in conjunction with scikit-learn’s utilities, such as GridSearchCV and cross_val_score.
To this end, we needed to take care of the following at the very least:
Inherit from scikit-learn’s BaseEstimator and ClassifierMixin classes.
Hide Code
class KNNClassifier(BaseEstimator, ClassifierMixin):
Implement the fit() and predict() methods with the correct validation logic and interface.
The X and y inputs should be validated using check_X_y() and check_classification_targets() during the fit() method.
The X input should be validated using check_array() during the predict() method, which must also check if the model has been fitted using check_is_fitted().
For more details on scikit-learn’s API conventions, refer to the documentation. Needless to say, while rolling our implemenations can be a great learning experience, it is often more efficient to use the optimized implementations provided by scikit-learn for production-level code.
Putting It All Together
The following script implements the entire KNN classifier, the cosine similarity and Euclidean distance functions, and runs a test for its compatibility with scikit-learn using the check_estimator() function.
Hide Code
from typing import Any, Dict, MutableSequence, Self, Union, Optionalimport numpy as npimport pandas as pdfrom scipy.sparse import csr_matrixfrom sklearn.base import BaseEstimator, ClassifierMixinfrom sklearn.metrics.pairwise import cosine_similarity, euclidean_distancesfrom sklearn.preprocessing import LabelEncoderfrom sklearn.utils.multiclass import check_classification_targetsfrom sklearn.utils.validation import check_array, check_is_fitted, check_X_yfrom sklearn.utils.estimator_checks import check_estimatorfrom tqdm import tqdmclass KNNClassifier(BaseEstimator, ClassifierMixin):""" K-Nearest Neighbors classifier. """def__init__(self, n_neighbors: int=5, weights: str="distance", metric: str="cosine", metric_params: Optional[Dict[str, Any]] =None, ) ->None:self.n_neighbors = n_neighborsself.weights = weightsself.metric = metricself.metric_params = metric_paramsdef fit(self, X: Union[csr_matrix, np.ndarray, pd.DataFrame], y: Union[np.ndarray, pd.Series, MutableSequence[Union[str, float]]], ) -> Self: X, y = check_X_y( X=X, y=y, accept_sparse="csr", ensure_2d=True, allow_nd=False, y_numeric=False, ) check_classification_targets(y)# Attributes that have been estimated from the data must end with a trailing underscoreself.X_train_ = Xself.label_encoder_ = LabelEncoder()self.y_train_ =self.label_encoder_.fit_transform(y)self.classes_ =self.label_encoder_.classes_ # Unique classes seen during fitself.n_features_in_ = X.shape[1] # Number of features seen during fitreturnselfdef predict(self, X: Union[csr_matrix, np.ndarray, pd.DataFrame]) -> np.ndarray: check_is_fitted(self, ["X_train_", "y_train_", "label_encoder_", "classes_", "n_features_in_"], ) X = check_array(X, accept_sparse="csr")# Handle edge case: only one class in training dataiflen(self.classes_) ==1:# The classes_ attribute was already in the format before encoding, so we can return it directlyreturn np.full(shape=X.shape[0], fill_value=self.classes_[0]) predictions = np.zeros(X.shape[0], dtype=int)for i, test_sample inenumerate(tqdm(X)):# Calculate distances to all training samples test_sample_reshaped = test_sample.reshape(1, -1) distances =self._compute_distances(test_sample_reshaped)# Identify the indices of the k nearest neighbors k_indices = np.argsort(distances, axis=-1)[: self.n_neighbors]# Predict class based on nearest neighbors prediction =self._predict_from_neighbors(k_indices, distances) predictions[i] = predictionreturnself.label_encoder_.inverse_transform(predictions)def _compute_distances(self, test_sample: Union[np.ndarray, csr_matrix] ) -> np.ndarray: metric_params = {} ifself.metric_params isNoneelseself.metric_paramsifself.metric =="cosine":return (1- cosine_similarity( X=test_sample, Y=self.X_train_, **metric_params ).flatten() )elifself.metric =="euclidean":return euclidean_distances( X=test_sample, Y=self.X_train_, **metric_params ).flatten()else:raiseNotImplementedError(f"Unsupported similarity function '{self.metric}'" )def _predict_from_neighbors(self, k_indices: np.ndarray, distances: np.ndarray ) ->int: k_nearest_labels =self.y_train_[k_indices]ifself.weights =="distance":# Inverse distance weighting, considering a small epsilon to avoid division by zero inv_distances =1/ (distances[k_indices] +1e-8) weighted_votes = np.bincount( k_nearest_labels, weights=inv_distances, minlength=len(self.classes_) )elifself.weights =="uniform":# Uniform weights (each neighbor contributes equally) weighted_votes = np.bincount(k_nearest_labels, minlength=len(self.classes_))else:raiseValueError(f"Unsupported weight function '{self.weights}'")returnint(np.argmax(weighted_votes))def main() ->int: knn_classifier = KNNClassifier() check_estimator(knn_classifier)print("\nKNNClassifier class is a valid estimator compatible with scikit-learn API!" )return0if__name__=="__main__": main()
News Group Multiclass Classification
To demonstrate the KNN classifier in action, we’ll use the 20 Newsgroups dataset available in scikit-learn. This dataset consists of approximately newsgroup documents across 20 different newsgroups. We will use a subset of the dataset containing three categories: soc.religion.christian, comp.graphics, and sci.med.
The goal is to train a KNN classifier to predict the category of a newsgroup post based on its content, which is vectorized using the TfidfVectorizer.
The features are the raw text data, which we will vectorize using the TfidfVectorizer. We will also reduce the dimensionality of the feature space using the TruncatedSVD transformer.
Hide Code
for i inrange(3):print("\n".join(twenty_train.data[i].split("\n")[:3]), "\n")
From: kene@acs.bu.edu (Kenneth Engel)
Subject: Re: Atheists and Hell
Organization: Boston University, Boston, MA, USA
From: ab@nova.cc.purdue.edu (Allen B)
Subject: Re: TIFF: philosophical significance of 42
Organization: Purdue University
From: grante@aquarius.rosemount.com (Grant Edwards)
Subject: Re: Krillean Photography
Reply-To: grante@aquarius.rosemount.com (Grant Edwards)
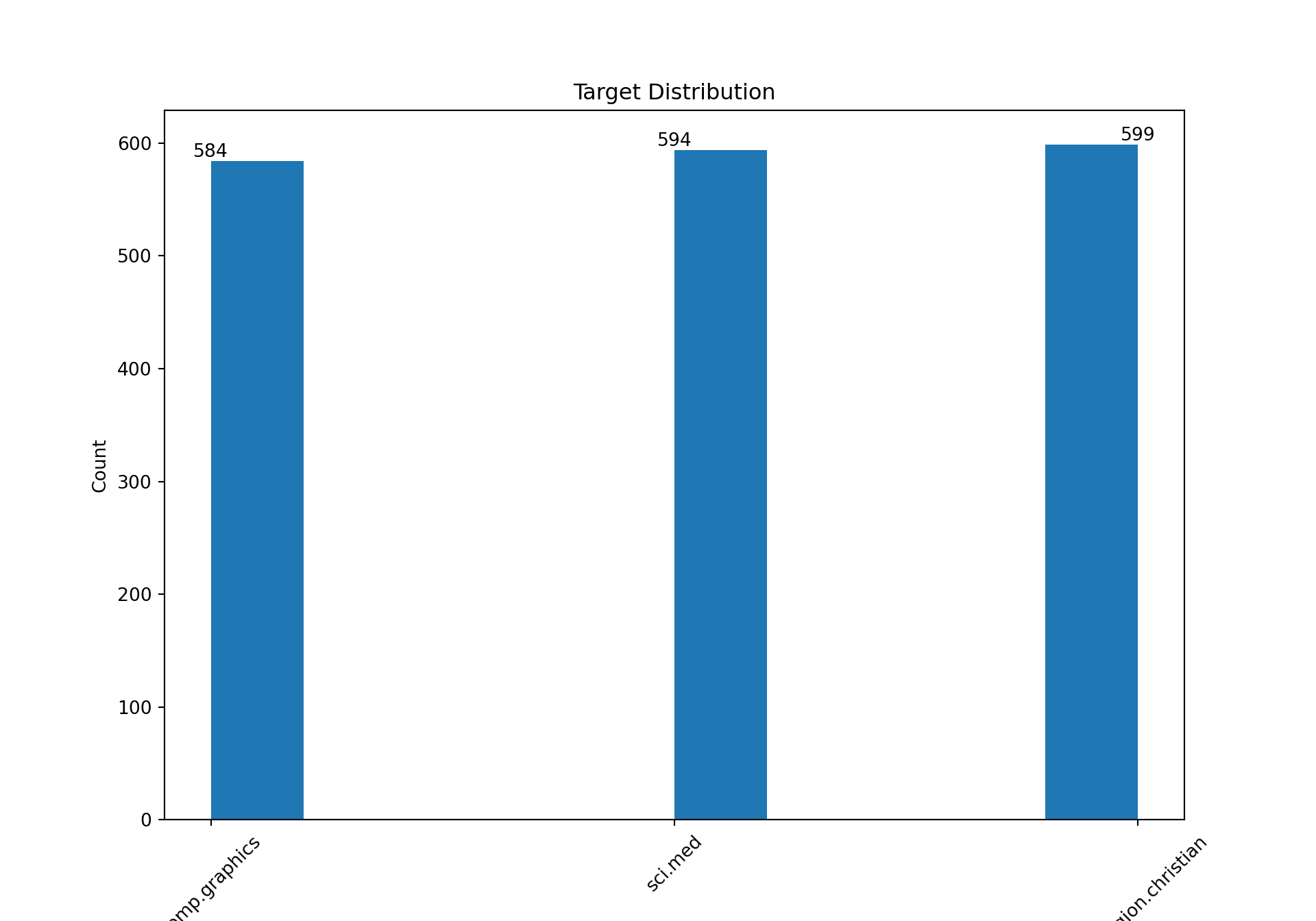
The target distribution for this toy dataset is as balanced as it can be compared to any real-world dataset.
Hide Code
target_names_map = {i: name for i, name inenumerate(twenty_train.target_names)}fig, ax = plt.subplots(figsize=(10, 7))ax.hist(twenty_train.target)ax.set_xticks(range(len(target_names_map)))ax.set_xticklabels(target_names_map.values(), rotation=45)# Add the count at the top of the barfor i, count inenumerate(np.bincount(twenty_train.target)): ax.text(i, count, str(count), ha="center", va="bottom");ax.set_xlabel("Category")ax.set_ylabel("Count")plt.title("Target Distribution")plt.show()
Custom KNN Classifier
Pipeline
For the pipeline, we carry out the following preprocessing steps:
Vectorize the text data using the TfidfVectorizer.
Reduce the dimensionality of the feature space using the TruncatedSVD. This is also known as Latent Semantic Analysis (LSA). This step can be a hyperparameter in the pipeline.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
We will perform a grid search to find the optimal hyperparameters for the KNN classifier. The hyperparameters we will tune are:
max_features: The maximum number of features to consider in the TfidfVectorizer.
lsa: The number of components to keep in the TruncatedSVD transformer. We will also include the option to use the original feature space without LSA using the passthrough option. See the documentation for more details.
n_neighbors: The number of neighbors to consider in the KNN classifier.
weights: The weight function to use in prediction. Possible values are uniform and distance.
metric: The similarity function to use. Possible values are euclidean and cosine.
Since the class distribution is balanced, accuracy is a valid metric to optimize.
Hide Code
cv_knn = StratifiedShuffleSplit(n_splits=3, test_size=0.2, random_state=rs)param_grid_knn = {"tfidf__max_features": [2048, 4096],"lsa": [TruncatedSVD(n_components=n) for n in [100, 150]]+ ["passthrough"], # Include 'passthrough' to test with or without LSA"knn__n_neighbors": [5, 10],"knn__weights": ["uniform", "distance"],"knn__metric": ["euclidean", "cosine"],}grid_search_knn = GridSearchCV( estimator=pipeline_knn, param_grid=param_grid_knn, scoring="accuracy", cv=cv_knn, n_jobs=1, verbose=1, refit=True, error_score="raise",)grid_search_knn.fit(twenty_train.data, twenty_train.target)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
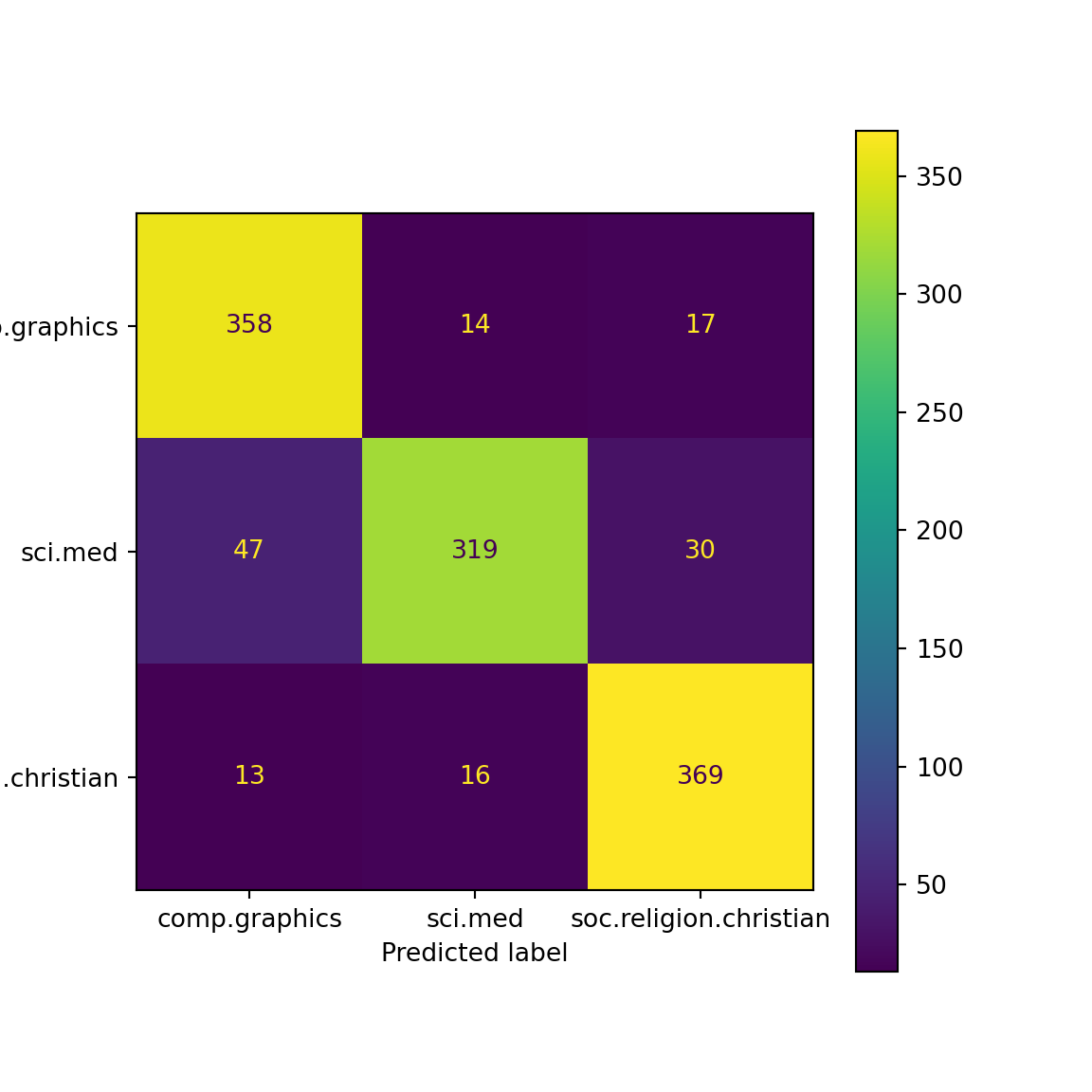
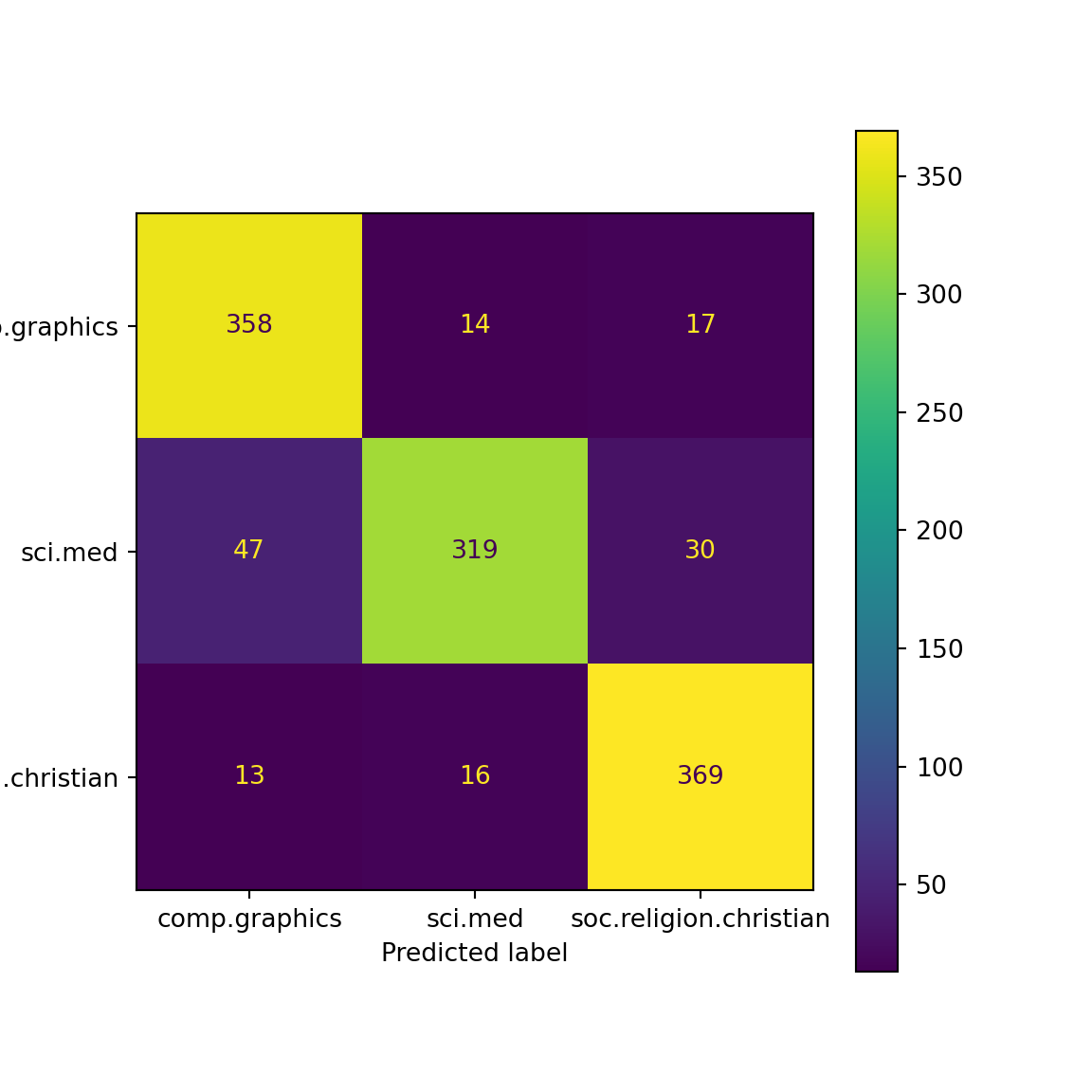
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay object at 0x14f1e3d50>
The scikit-learn implementation of the KNN classifier exactly matches the results of our custom implementation, demonstrating the correctness of our implementation.