For a machine-learning based portfolio optimization algorithm, see this post.
In a previous post, we covered portfolio optimization and its implementations in R. In this post, We will tackle the problem of portfolio optimization using Python, which offers some elegant implementations. Much of the structure of the post is gleaned from Yves Hilpisch’s awesome book Python for Finance. Our analysis essentially boils down to the following tasks:
Import financial data via API’s
Compute returns and statistics
Simulate a random set of portfolios
Construct a set of optimal portfolios using Markowitz’s mean-variance framework
Visualize the set of optimal portfolios using the plotly library
Backtest the performance of the optimal portfolio
Tools from The Python Ecosystems
We need the following Python libraries and packages:
from datetime import datetime, timedeltaimport numpy as npimport pandas as pdimport yfinance as yfimport scipy.optimize as scoimport scipy.interpolate as sciimport matplotlib.pyplot as pltimport matplotlib.ticker as tickerimport plotly.graph_objects as goimport plotly.offline as pyopyo.init_notebook_mode(connected=True)
For our sample, we select 12 different equity assets with exposure to all of the GICS sectors— energy, materials, industrials, utilities, healthcare, financials, consumer discretionary, consumer staples, information technology, communication services, and real estate. The sampling period will cover the last 10 years, starting from 2021-09-15, ensuring comprehensive historical data for analysis.
[ 0% ]
[******** 17% ] 2 of 12 completed
[************ 25% ] 3 of 12 completed
[**************** 33% ] 4 of 12 completed
[******************** 42% ] 5 of 12 completed
[**********************50% ] 6 of 12 completed
[**********************58%*** ] 7 of 12 completed
[**********************67%******* ] 8 of 12 completed
[**********************75%*********** ] 9 of 12 completed
[**********************83%*************** ] 10 of 12 completed
[**********************92%******************* ] 11 of 12 completed
[*********************100%***********************] 12 of 12 completed
Hide Code
daily_prices.columns = symbols
dates
XOM
SHW
JPM
AEP
UNH
AMZN
KO
BA
AMT
DD
TSN
SLG
2011-09-18
21.77181
39.96898
12.0845
52.15866
11.191030
21.79780
22.54726
21.55978
37.14155
12.85485
39.51577
41.63576
2011-09-19
22.22431
39.92556
11.6625
51.67894
11.009353
21.63677
22.59844
21.43274
36.95898
12.54914
39.42084
41.81088
2011-09-20
21.72540
39.16541
11.5935
49.61374
10.310925
20.35534
22.16022
20.62429
34.44065
12.24342
37.98103
40.65841
2011-09-21
21.51076
37.86231
11.1615
47.74368
9.293562
19.63747
21.69322
20.20851
32.19078
12.16140
37.25320
39.11613
2011-09-22
21.72540
37.85506
11.1805
48.38599
9.499456
19.85216
21.56528
20.60985
32.48611
12.25834
37.65670
39.15570
Next, we find the simple daily returns for each of the 12 assets using the pct_change() method, since our data object is a Pandas DataFrame. We use simple returns since they have the property of being asset-additive, which is necessary since we need to compute portfolios returns:
Hide Code
# Compute daily simple returnsdaily_returns = ( daily_prices.pct_change() .dropna(# Drop the first row since we have NaN's axis =0, how ='any', inplace =False ))
dates
XOM
SHW
JPM
AEP
UNH
AMZN
KO
BA
AMT
DD
TSN
SLG
2011-09-19
0.0207836
-0.0010862
-0.0349208
-0.0091973
-0.0162342
-0.0073873
0.0022701
-0.0058925
-0.0049156
-0.0237822
-0.0024021
0.0042061
2011-09-20
-0.0224487
-0.0190393
-0.0059164
-0.0399623
-0.0634394
-0.0592246
-0.0193915
-0.0377204
-0.0681384
-0.0243613
-0.0365243
-0.0275639
2011-09-21
-0.0098798
-0.0332715
-0.0372623
-0.0376922
-0.0986685
-0.0352670
-0.0210738
-0.0201599
-0.0653260
-0.0066992
-0.0191628
-0.0379326
2011-09-22
0.0099784
-0.0001915
0.0017023
0.0134533
0.0221545
0.0109327
-0.0058980
0.0198604
0.0091742
0.0079707
0.0108311
0.0010115
2011-09-25
0.0085449
0.0231406
0.0279058
0.0420100
0.0416489
0.0696181
0.0198754
0.0686463
0.0231408
0.0273723
0.0254193
0.0347711
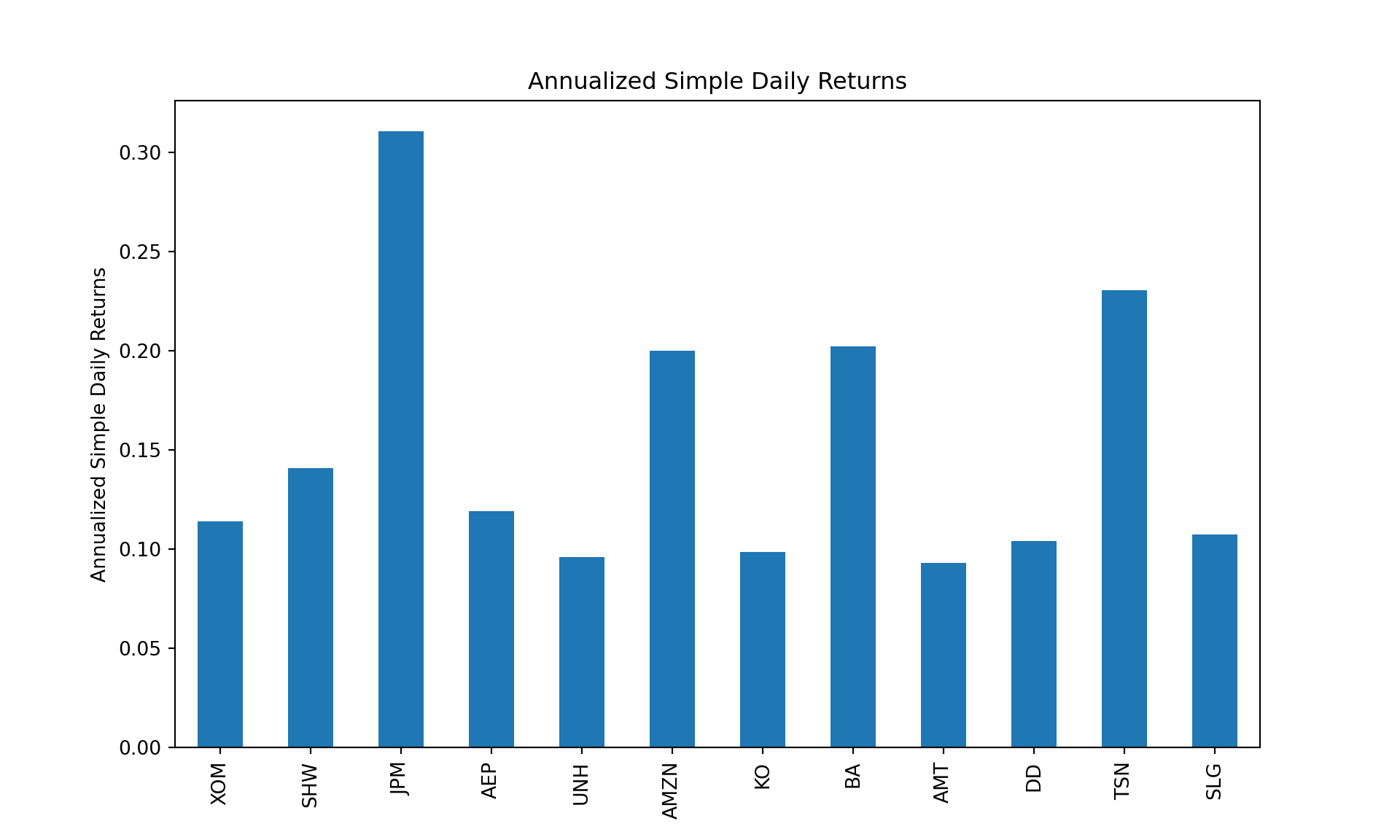
The simple daily returns may be visualized using line charts, density plots, and histograms, which are covered in my other post on visualizing asset data. Even though the visualizations in that post use the ggplot2 package in R, the plotnine package, or any other Python graphics librarires, can be employed to produce them in Python. For now, let us annualize the daily returns over the 10-year period ending in 2026-05-16. We assume the number of trading days in a year is computed as follows:
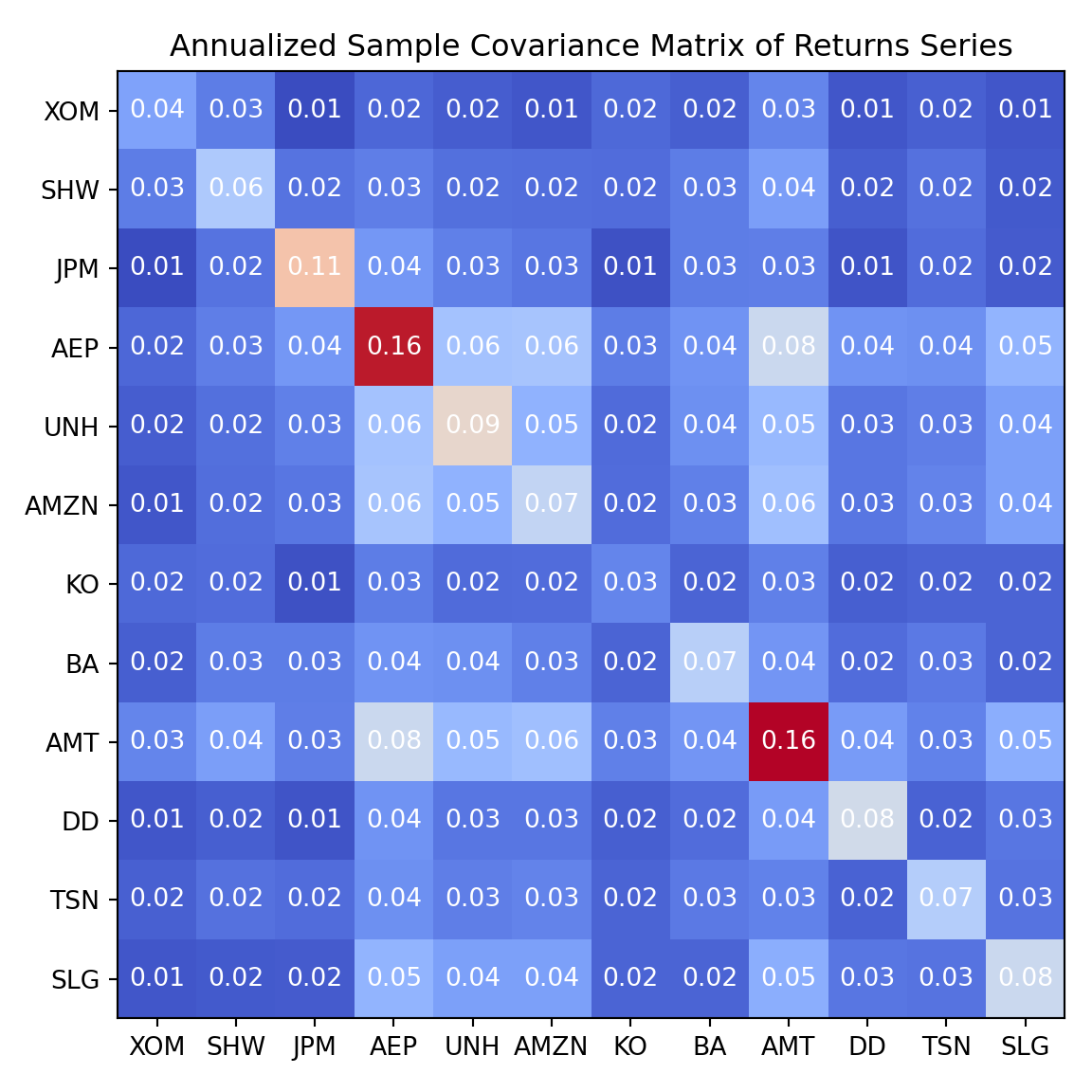
As can be seen, there are significant differences in the annualized performances between these assets. The annualized variance-covariance matrix of the returns can be computed using built-in pandas method cov. Note that while the sample covariance matrix is an unbiased estimator of the population covariance matrix, it can be subject to significant estimation error, especially when the number of assets is large relative to the number of observations. In our case, because of the relatively long sample period, the estimation error is likely to be small:
Hide Code
annualized_sample_covariance = daily_returns.cov() *253fig, ax = plt.subplots();cax = ax.matshow(annualized_sample_covariance, cmap="coolwarm");ax.xaxis.set_ticks_position('bottom');ax.set_xticks(np.arange(len(annualized_sample_covariance.columns)));ax.set_yticks(np.arange(len(annualized_sample_covariance.columns)));ax.set_xticklabels(annualized_sample_covariance.columns);ax.set_yticklabels(annualized_sample_covariance.columns);for i inrange(annualized_sample_covariance.shape[0]):for j inrange(annualized_sample_covariance.shape[1]):# Ensure text can be easily seen value = annualized_sample_covariance.iloc[i, j] color ="white"if value <0.5else"black" ax.text(j, i, f"{value:.2f}", ha="center", va="center", color=color);plt.title("Annualized Sample Covariance Matrix of Returns Series");plt.tight_layout();plt.show()
The variance-covariance matrix of the returns will be needed to compute the variance of the portfolio returns.
The Optimization Problem
The portfolio optimization problem, therefore, given a universe of assets and their characteristics, deals with a method to spread the capital between them in a way that maximizes the return of the portfolio per unit of risk taken. There is no unique solution for this problem, but a set of solutions, which together define what is called an efficient frontier— the portfolios whose returns cannot be improved without increasing risk, or the portfolios where risk cannot be reduced without reducing returns as well. The Markowitz model for the solution of the portfolio optimization problem has a twin objective of maximizing return and minimizing risk, built on the Mean-Variance framework of asset returns and holding the basic constraints, which reduces to the following:
Minimize Risk given Levels of Return
subject to
Maximize Return given Levels of Risk
subject to
In absence of other constraints, the above model is loosely referred to as the “unconstrained” portfolio optimization model. Solving the mathematical model yields a set of optimal weights representing a set of optimal portfolios. The solution set to these two problems is a hyperbola that depicts the efficient frontier in the -diagram.
Monte Carlo Simulation
The first task is to simulate a random set of portfolios to visualize the risk-return profiles of our given set of assets. To carry out the Monte Carlo simulation, we define two functions that both take as inputs a vector of asset weights and output the annualized expected portfolio return and standard deviation:
Annualized Returns
Hide Code
# Function for computing portfolio returndef portfolio_returns(weights) ->float:returnfloat((np.sum(daily_returns.mean() * weights)) *253)
Annualized Standard Deviation
Hide Code
# Function for computing standard deviation of portfolio returnsdef portfolio_sd(weights) ->float:returnfloat(np.sqrt(np.transpose(weights) @ (daily_returns.cov() *253) @ weights))
Next, we use a for loop to simulate random vectors of asset weights, computing the expected portfolio return and standard deviation for each permutation of random weights. Again, we ensure that each random weight vector is subject to the long-positions-only and full-investment constraints.
Monte Carlo Simulation
The empty containers we instantiate are lists, which are mutable. This makes python lists more memory efficient than growing vectors in R, provided the number of simulations isn’t excessively large (i.e., in the millions). In such cases, resizing and over-allocation costs would be huge, and we should vectorize the potoflio_returns and portfolio_sd functions to leverage NumPy’s vectorized operations.
Hide Code
num_portfolios =5000num_assets =len(symbols)# Generate random weights for all portfoliosrandom_weights = np.random.random((num_portfolios, num_assets))# Normalize the weights so that the sum of weights for each portfolio equals 1random_weights /= np.sum(random_weights, axis=1, keepdims=True)list_portfolio_returns = []list_portfolio_sd = []# Monte Carlo simulation: loop through each set of random weightsfor weights in random_weights: list_portfolio_returns.append(portfolio_returns(weights)) # Calculate and store returns list_portfolio_sd.append(portfolio_sd(weights)) # Calculate and store standard deviations (risk)port_returns = np.array(list_portfolio_returns)port_sd = np.array(list_portfolio_sd)
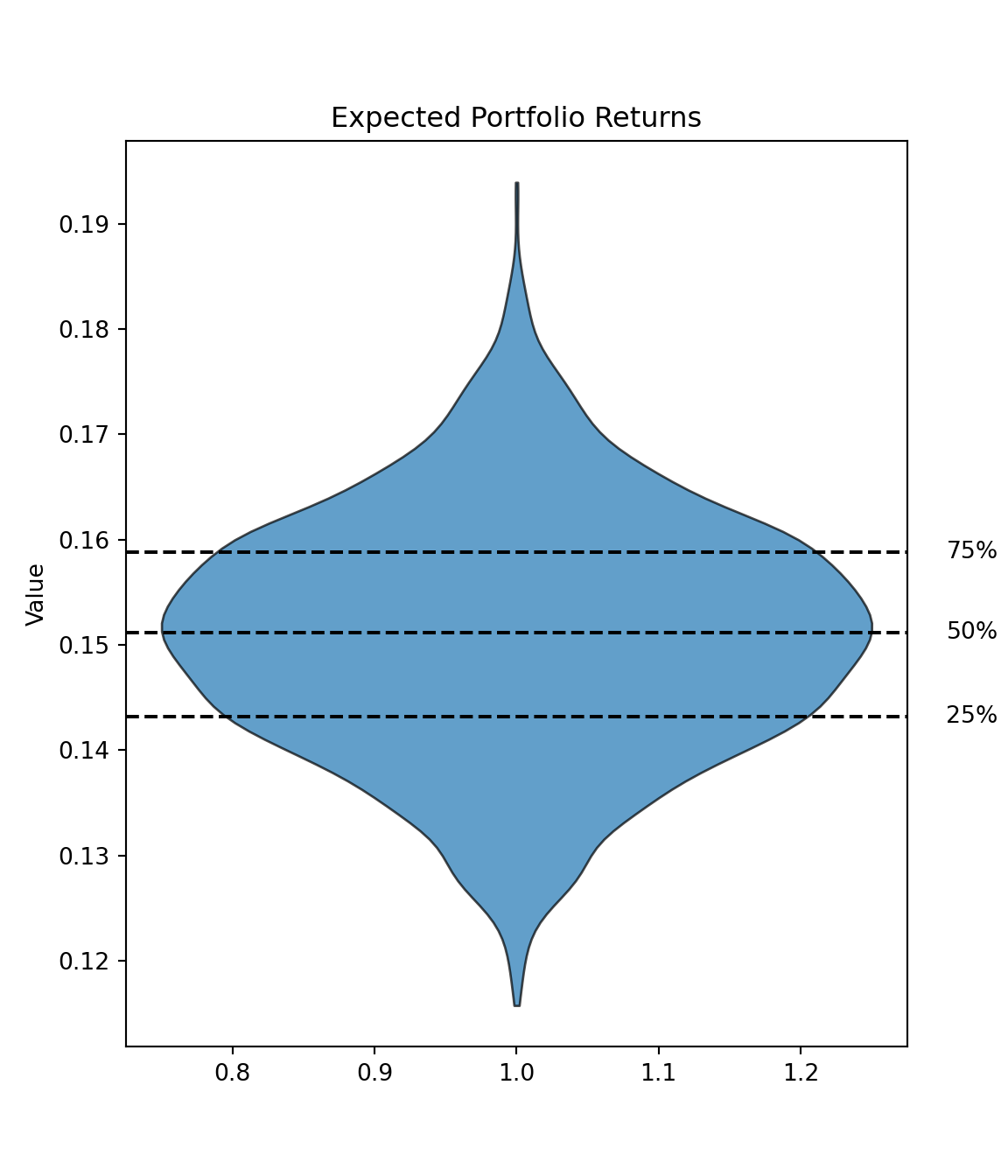
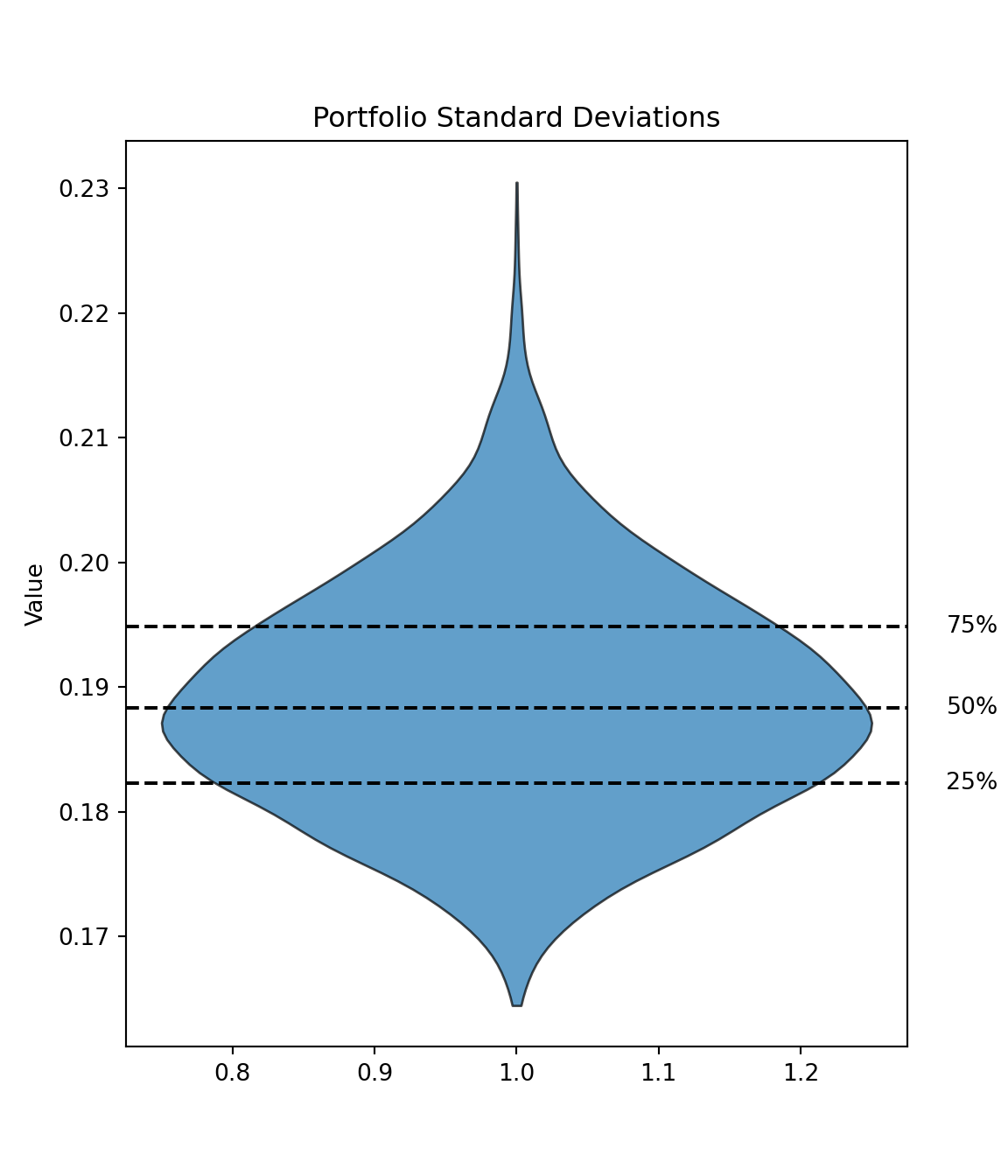
Let us examine the simulation results. In particular, the highest and the lowest expected portfolio returns are as follows:
Hide Code
def plot_violin_with_quantiles(data: np.ndarray, title: str) ->None: fig, ax = plt.subplots(figsize=(6, 7)) parts = ax.violinplot(data, showmeans=False, showmedians=False, showextrema=False)# Customize the violin plot appearancefor pc in parts['bodies']: pc.set_facecolor('#1f77b4') pc.set_edgecolor('black') pc.set_alpha(0.7)# Calculate and annotate quantiles quantiles = np.percentile(data, [25, 50, 75])for q, label inzip(quantiles, ['25%', '50%', '75%']): ax.axhline(q, color='black', linestyle='--') ax.text(1.05, q, f'{label}', transform=ax.get_yaxis_transform(), ha='left', va='center')# Set labels and title ax.set_ylabel('Value') ax.set_title(title) plt.show()
Each point in the diagram above represents a permutation of expected-return-standard-deviation value pair. The points are color coded such that the magnitudes of the Sharpe ratios, defined as , can be readily observed for each expected-return-standard-deviation pairing. For simplicity, we assume that . It could be argued that the assumption here is restrictive, so I explored using a different risk-free rate in my previous post.
The Optimal Portfolios
Solving the optimization problem defined earlier provides us with a set of optimal portfolios given the characteristics of our assets. There are two important portfolios that we may be interested in constructing— the minimum variance portfolio and the maximal Sharpe ratio portfolio. In the case of the maximal Sharpe ratio portfolio, the objective function we wish to maximize is our user-defined Sharpe ratio function. The constraint is that all weights sum up to 1. We also specify that the weights are bound between 0 and 1. In order to use the minimization function from the SciPy library, we need to transform the maximization problem into one of minimization. In other words, the negative value of the Sharpe ratio is minimized to find the maximum value; the optimal portfolio composition is therefore the array of weights that yields that maximum value of the Sharpe ratio.
Hide Code
# User defined Sharpe ratio function# Negative sign to compute the negative value of Sharpe ratiodef sharpe_fun(weights):return- (portfolio_returns(weights) / portfolio_sd(weights))
We will use a list of dictionaries to represent the constraints:
Hide Code
# We use an anonymous lambda functionconstraints = [{'type': 'eq', 'fun': lambda x: np.sum(x) -1}]
Next, the bound values for the weights:
Hide Code
# This creates 12 tuples of (0, 1), creating a sequence of (min, max) pairsbounds =tuple( (0, 1) for w in weights)
We also need to supply a starting sequences of weights, which essentially functions as an initial guesses. For our purposes, this will be an equal weight array:
Hide Code
# Repeat the list with the value (1 / 12) 12 times, and convert list to arrayequal_weights = np.array( [1/len(symbols)] *len(symbols))
# Minimization resultsmax_sharpe_results = sco.minimize(# Objective function fun = sharpe_fun, # Initial guess, which is the equal weight array x0 = equal_weights, method ='SLSQP', bounds = bounds, constraints = constraints)
The optimization results is an isntance of scipy.optimize.optimize.OptimizeResult, which contains many objects. The object of interest to us is the weight composition array, which we employ to construct the maximal Sharpe ratio portfolio:
Hide Code
# Extract the weight composition arraymax_sharpe_results["x"]
Expected Return Standard Deviation Sharpe Ratio
0 0.162526 0.148197 1.09669
Efficient Frontier
As an investor, one is generally interested in the maximum return given a fixed risk level or the minimum risk given a fixed return expectation. As mentioned in the earlier section, the set of optimal portfolios— whose expected portfolio returns for a defined level of risk cannot be surpassed by any other portfolio— depicts the so-called efficient frontier. The Python implementation is to fix a target return level and, for each such level, minimize the volatility value. For the optimization, we essentially “fit” the twin-objective described earlier into an optimization problem that can be solved using quadratic programming. (The objective function is the portfolio standard deviation formula, which is a quadratic function) Therefore, the two linear constraints are the target return (a linear function) and that the weights must sum to 1 (another linear function). We will again use a tuple of dictionaries to represent the constraints:
Hide Code
# The arguments x will be the weightsconstraints = ( {'type': 'eq', 'fun': lambda x: portfolio_returns(x) - target}, {'type': 'eq', 'fun': lambda x: np.sum(x) -1})
The full-investment and long-positions-only specifications will remain unchanged throughout the optimization process, but the value the name target is bound to will be different during each iteration. Since dictionaries are mutable, the first constraint dictionary will be updated repeatedly during the minimization process. However, because tuples are immutable, the references held by the constraints tuple will always point to the same objects. This nuance makes the implementation Pythonic. We constrain the weights such that all weights fall within the interval :
Hide Code
bounds =tuple( (0, 1) for w in weights)
We will use the scipy.optimize.minimize function again and the Sequential Least Squares Programming (SLSQP) method for the minimization:
Hide Code
# Initialize an array of target returnstarget = np.linspace( start =0.15, stop =0.30, num =100)obj_sd = []for target in target:# Minimize the twin-objective function given the target expected return min_result_object = sco.minimize( fun = portfolio_sd, x0 = equal_weights, method ='SLSQP', bounds = bounds, constraints = constraints )# Extract the objective value and append it to the output container obj_sd.append(min_result_object['fun'])obj_sd = np.array(obj_sd)# Rebind target to a new array objecttarget = np.linspace( start =0.15, stop =0.30, num =100)
When we plot the efficient frontier, we may wish to highlight the two portfolios in the plot— the maximal Sharpe ratio and the minimum variance portfolios:
Evidently, the efficient frontier is comprised of all optimal portfolios with a higher return than the global minimum variance portfolio. These portfolios dominate all other sub-optimal portfolios in terms of expected returns given a certain risk level.
Capital Market Line
Now that we have determined a set of efficient portfolios of risky assets, we may be interested in adding a risk-free asset to the mix. By adjusting the wealth allocation for the risk-free asset, it is possible for us to achieve any risk-return profile that lies on the straight line (in the diagram) between the risk-free asset and an efficient portfolio. This is called the capital market line, which is drawn from the point of the risk-free asset to the feasible region for risky assets. The capital market line has the equation:
where
The problem then becomes: which efficient portfolio on the efficient frontier should we use? The answer is the tangency portfolio, at which point on the efficient frontier the slope of the tangent line is equal to that of the capital market line. In order to find the slope of the tangent line, a functional approximation of the efficient frontier and its first derivative must be obtained. Yves Hilpisch’s book recommends the use of cubic splines interpolation to obtain a continuously differentiable functional approximation of the efficient frontier, . To carry out cubic splines interpolation, we need to create two array objects representing the expected returns and standard deviations of each of the efficient portfolios on the efficient frontier. In other words, we need to exclude from obj_sd and target (our two arrays of optimization results) the portfolios whose standard deviations are greater than that of the minimum variance portfolio but whose expected returns are smaller; they are not optimal and are therefore not on the efficient frontier:
Hide Code
# Use np.argmin() to find the index of the minimum variance portfolio and take a slice starting from that point, excluding previous elementsefficient_sd = obj_sd[np.argmin(a = obj_sd):]# Take a slice of target returns starting from the minimum variance portfolio index and exclude previous elementsefficient_returns = target[np.argmin(a = obj_sd):]
We will leverage the the facilities from the scipy.interpolate sub-package, in particular, the splrep() function. Given the set of data points , the scipy.interpolate.splrep() function determine a smooth spline approximation of degree . The function will return a tuple with three elements— the vector of knots , the B-spline coefficients , and the degree of the spline .
Hide Code
# Cubic spline interpolationtck = sci.splrep( x = np.sort(efficient_sd), y = efficient_returns, k =3)
Next, we use the scipy.interpolate.splev() function to define the functional approximation and the first derivative of the efficient frontier— and . Given the knots and the B-spline coefficients, the function scipy.interpolate.splev() evaluates the value of the smoothing polynomial and its derivative:
Hide Code
# Define functional approximation of efficient frontierdef f(x):return sci.splev( x = x, tck = tck, der =0 )# Define first derivative of the efficient frontierdef df(x):return sci.splev( x = x, tck = tck, der =1 )
Let us re-examine the equation for the capital market line. Notice that the line is a linear equation of the form:
where the parameters are as follows:
There are three unknown parameters and therefore we must have three equations to solve for the values of these parameters:
To solve the system, we will use the scipy.optimize.fsolve() function, which finds the roots of any input function. First, we need to define a function that returns the values of all three equations given a set of parameters . The set of parameters can be represented using a python list where , , and :
The function scipy.optimize.fsolve() returns an ndarray object, which is the solution set to the linear system above:
Hide Code
# Solve the linear systemsol_set = sco.fsolve(# Equations to solve for func = sys_eq,# Initial guess for p# This can be determined by trial and error or from the plot above (may take more than one try) x0 = [0.05, 1, 0.15])
As a sanity check, we an plug our solution set into our user defined function sys_eq to see if the results are indeed zeros:
Hide Code
# Sanity checknp.round( sys_eq( p = sol_set ),4)
array([ 0., -0., 0.])
We have confirmed that our solution set for the linear system is as follows:
0.01
1.4299
0.1766
Tangency Portfolio
To find the tangency portfolio, we use the same routine when we solved for the efficient frontier. We can compute the target return using the value from our solution set above. The rest is exactly the same as before.
The fun key of the first contstraint dictionary now uses the f (functional approximation of the efficient frontier) function and (the value of the solution set) to compute the target return:
Expected Return Standard Deviation Sharpe Ratio
0 0.262572 0.176635 1.486529
Finally, with these parameters, we can now plot the capital market line on the diagram. Similar to our approach earlier, we first define a function whose body is the linear equation of the capital market line. This function takes as its argument the x values of the diagram:
Hide Code
# Capital market linedef cml(x):return sol_set[0] + sol_set[1] * x
Next, create arrays of plotting data:
Hide Code
# Standard deviationscml_sd = np.linspace( start =0, stop =0.25, num =100)# Expected returnscml_exp_returns = cml(x = cml_sd)
Move to R and plot the capital market line on the diagram:
You may wish to zoom in to see more clearly the values for the portfolios. Fortunately, the plotly package allows for interacting with the plots; hover over the plots to examine your options.
Walk-Forward Backtesting
So far, the metrics for the optimal portfolios are computed one the entire sample. In practice, however, the real test is how that portfolio performs out of sample. We can turn our static Markowitz weights into a walk-forward trading strategy and evaluate it against a benchmark.
The steps are as follows:
Estimation window: Look back L years (in this post, we use 3 years) to estimate mean and covariance.
Rebalancing rule: Max-Sharpe weights, long-only, fully-invested, re-optimized at each month-end.
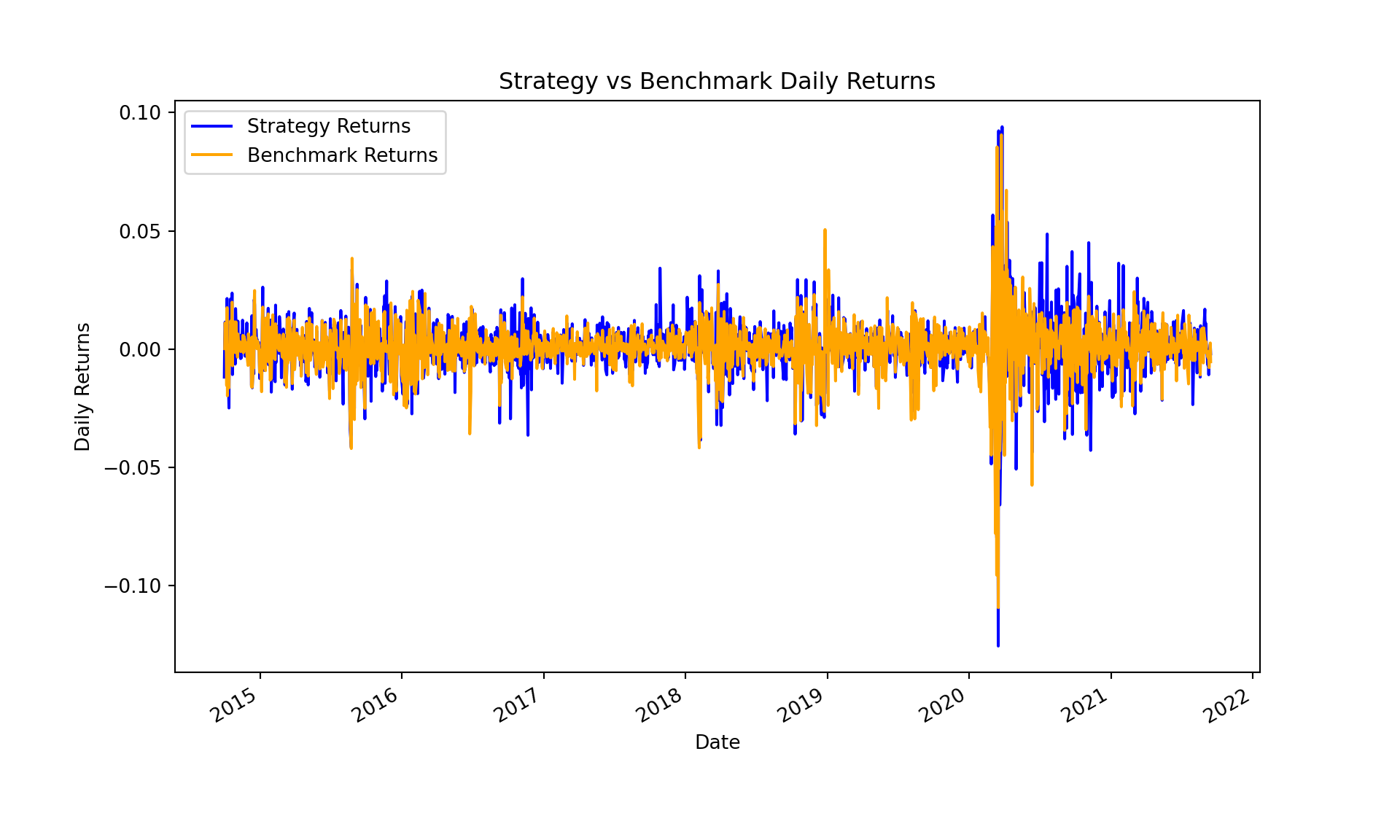
Backtest engine: Apply weights from the next open (to avoid look-ahead bias) and compare to SPY, which is an ETF that tracks the S&P 500 index.
Evaluation: Visualize the cumulative returns of the strategy vs the benchmark.
Note: this is one of the simplest possible backtests. One of the main limitations is that it evaluates the strategy on one path, whereas the real world is much more volatile and uncertain. For a survey on more advanced techniques, see this paper.
Generate Rolling Max-Sharpe Weights
We use the daily_returns function and symbols list created earlier to generate the rolling max-Sharpe weights. Some parameters:
TRADING_DAYS =253LOOKBACK_YEARS =3REBAL_FREQ = pd.tseries.offsets.BusinessMonthEnd() BENCH_TICKER ="SPY"def max_sharpe_weights(window_returns: pd.DataFrame) -> np.ndarray:""" Long-only, sum-to-1 max-Sharpe optimization. Parameters ---------- window_returns : pd.DataFrame DataFrame of returns for the assets in the window. Returns ------- np.ndarray Weights for the assets that maximize the Sharpe ratio. """ mu, cov = window_returns.mean() * TRADING_DAYS, window_returns.cov() * TRADING_DAYS n, x0 =len(mu), np.full(len(mu), 1/len(mu))def neg_sr(w) ->float: ret = w @ mu.values vol = np.sqrt(w @ cov.values @ w) +1e-12# Tiny jitter to avoid division by zeroreturn-ret / vol constraints = [{"type": "eq", "fun": lambda w: w.sum() -1}] bounds = [(0, 1)] * n opt_results = sco.minimize(neg_sr, x0, method="SLSQP", bounds=bounds, constraints=constraints)# Default to equal weights if optimization failsreturn opt_results.x if opt_results.success else x0
We resample the daily returns to get the business month-end returns, which will be used for rebalancing. The lookback period is defined as LOOKBACK_YEARS * TRADING_DAYS, which gives us the number of trading days in the lookback period. We then compute the max-Sharpe weights for each month-end date using the max_sharpe_weights function defined above.
Rolling through the month-end dates, we compute the max-Sharpe weights for each month-end date using the max_sharpe_weights function. The assumption is that the weights are re-optimized at each month-end based on the past LOOKBACK_YEARS of data.
The results are first stored in a dictionary where the keys are the rebalance dates and the values are the weights for each asset at that date:
Hide Code
weight_snapshots = {}for d in month_ends: window = daily_returns.loc[:d].tail(int(lookback_days))iflen(window) < lookback_days: # Skip until we have full historycontinue weight_snapshots[d] = max_sharpe_weights(window)weights_data = pd.DataFrame.from_dict( weight_snapshots, orient="index", columns=symbols).sort_index()weights_data.index.name ="rebalance_date"
XOM
SHW
JPM
AEP
UNH
AMZN
KO
BA
AMT
DD
TSN
SLG
2014-09-29 20:00:00
0.1150263
0.0895082
0.0000000
0.1313899
0
0.0000000
0
0.4041073
0.0000000
0.1427697
0.1171985
0
2014-10-30 20:00:00
0.2192971
0.0747689
0.0000000
0.0887048
0
0.0000000
0
0.3417950
0.0000000
0.1046536
0.1707806
0
2014-11-27 19:00:00
0.1820850
0.0962253
0.0000000
0.1019928
0
0.0018607
0
0.3204067
0.0000000
0.0853354
0.2120940
0
2014-12-30 19:00:00
0.2282953
0.0203953
0.0000000
0.0555523
0
0.0357944
0
0.3845660
0.0208252
0.0509803
0.2035911
0
2015-01-29 19:00:00
0.2732721
0.0000000
0.0126192
0.1136183
0
0.0000000
0
0.3386761
0.0000000
0.0626931
0.1991213
0
2015-02-26 19:00:00
0.1967408
0.0001789
0.0333686
0.1407739
0
0.0000000
0
0.3444393
0.0000000
0.0937192
0.1907794
0
In the dataframe above, each row corresponds to a month-end rebalance date, and each column corresponds to an asset in the portfolio. The values are the optimized weights (with respect to maximizing the Sharpe ratio) assigned to each asset at that rebalance date. By construction, all weights are and sum to 1, so no leverage is assumed.
We can verify that the weights sum to 1 for each rebalance date:
Next, we need to transform the monthly weights into daily weights again. This is done by forward-filling the weights until the next rebalance date, and then shifting the weights by one day to ensure that the weights are applied from the next trading day after the signal is generated. This avoids look-ahead bias, as we do not use the weights from the same day they are calculated.
Without shift(1), we would be using information from day T to make decisions on day T. This creates an unrealistic scenario where we’re using the same day’s market close data to decide the portfolio weights for that same day. In reality:
The optimal weights are calculated using data available at the END of day T
We can only implement those weights starting from day T+1
There’s always a delay between signal generation and execution
Hide Code
daily_weights = ( weights_data.reindex(daily_returns.index, method="ffill") # Hold until next rebalance .shift(1) # Start the day *after* the signal .dropna(how="all"))
XOM
SHW
JPM
AEP
UNH
AMZN
KO
BA
AMT
DD
TSN
SLG
2014-09-30 20:00:00
0.1150263
0.0895082
0
0.1313899
0
0
0
0.4041073
0
0.1427697
0.1171985
0
2014-10-01 20:00:00
0.1150263
0.0895082
0
0.1313899
0
0
0
0.4041073
0
0.1427697
0.1171985
0
2014-10-02 20:00:00
0.1150263
0.0895082
0
0.1313899
0
0
0
0.4041073
0
0.1427697
0.1171985
0
2014-10-05 20:00:00
0.1150263
0.0895082
0
0.1313899
0
0
0
0.4041073
0
0.1427697
0.1171985
0
2014-10-06 20:00:00
0.1150263
0.0895082
0
0.1313899
0
0
0
0.4041073
0
0.1427697
0.1171985
0
2014-10-07 20:00:00
0.1150263
0.0895082
0
0.1313899
0
0
0
0.4041073
0
0.1427697
0.1171985
0
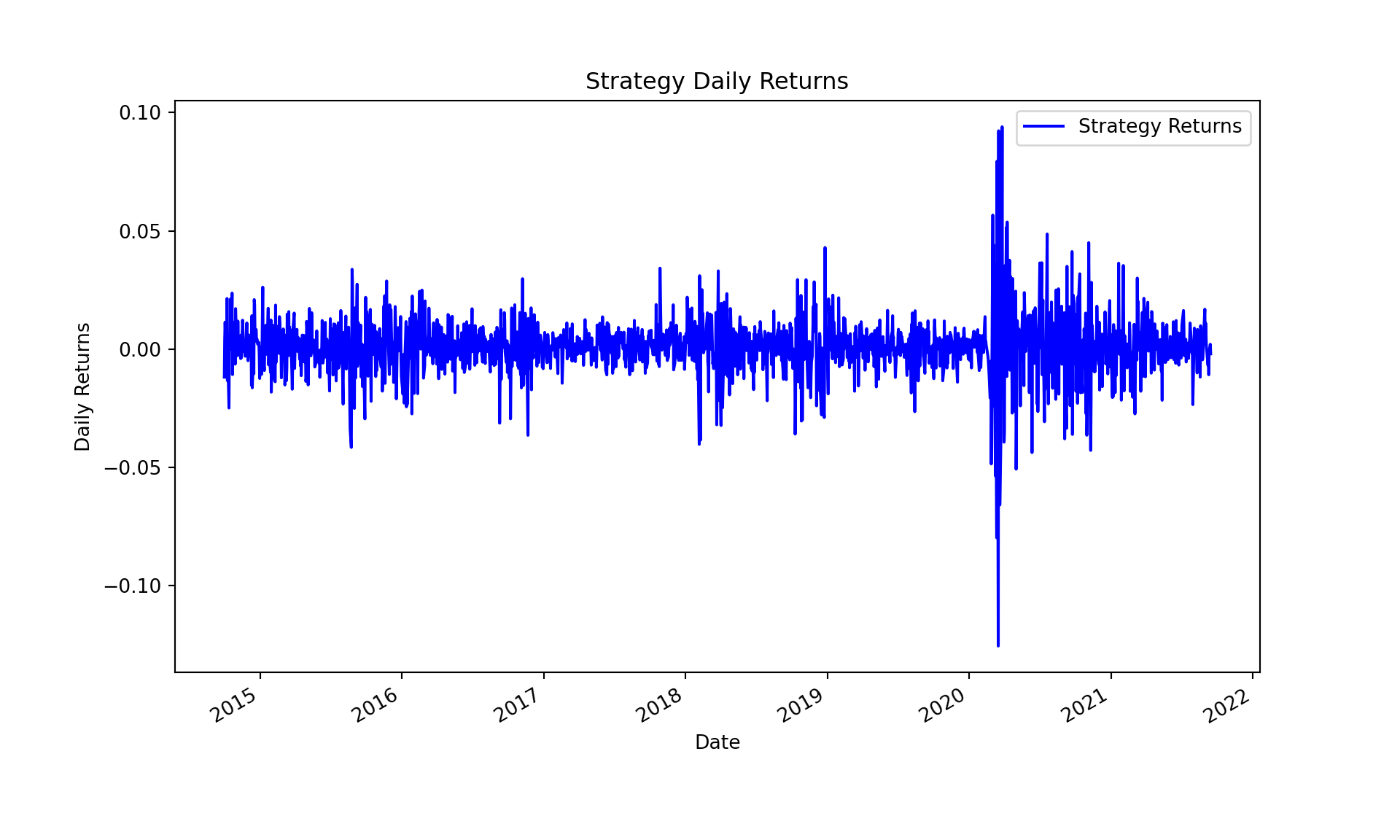
The daily returns of the strategy can be obtained by multiplying the daily weights with the daily returns of the assets. The result is a series of daily returns for the strategy, which we can then use to evaluate the performance of the portfolio.
First, align the indices of both series to ensure they cover the same dates and convert the indices to tz-aware datetime objects.
Hide Code
strategy_returns, benchmark_returns = strategy_returns.align( benchmark_returns, join="inner"# Keep only dates common to both)strategy_returns.index = strategy_returns.index.tz_localize("UTC")benchmark_returns.index = benchmark_returns.index.tz_localize("UTC")
At this point we have two aligned pd.Series objects:
object
description
strategy_returns
daily returns of the rolling Markowitz strategy
benchmark_returns
daily returns of SPY
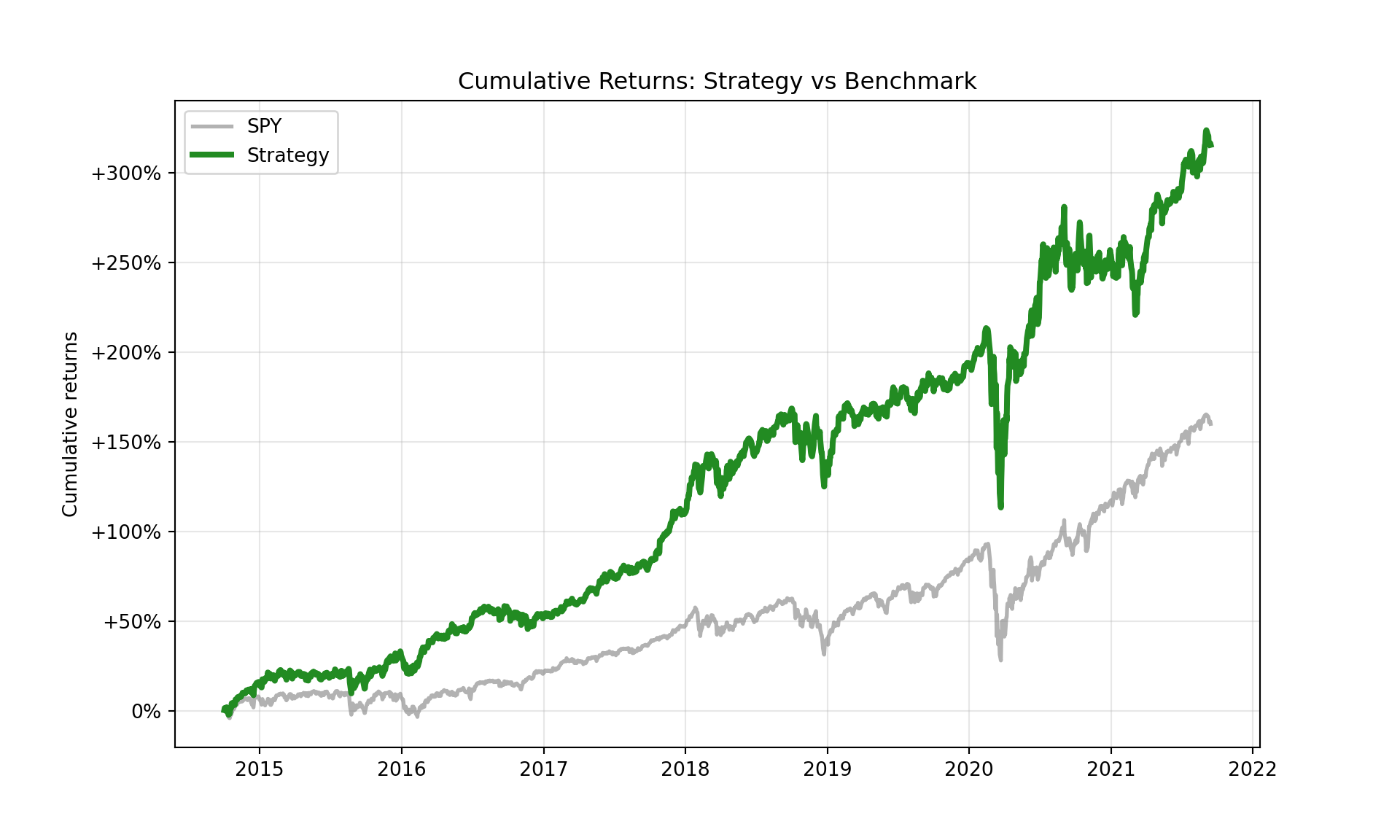
We can now plot the cumulative returns of the strategy and the benchmark, with a clear distinction between the in-sample and out-of-sample periods. The cumulative returns are calculated by taking the cumulative product of the daily returns plus one.
Hide Code
def plot_rolling_returns( returns: pd.Series, benchmark: pd.Series |None=None, live_start_date: str| pd.Timestamp |None=None, logy: bool=False, ax: plt.Axes |None=None,) -> plt.Axes:""" Plot cumulative returns of a strategy with optional benchmark overlay. Parameters ---------- returns : pd.Series Daily strategy returns (non-cumulative, index = DatetimeIndex). benchmark : pd.Series, optional Daily benchmark returns to overlay (same index as `returns`). live_start_date : str | pd.Timestamp, optional Date that separates backtest vs. live trading. logy : bool, default False Plot y-axis on log scale. ax : matplotlib.axes.Axes, optional Pre-existing axes to plot on. Returns ------- ax : matplotlib.axes.Axes The axis containing the plot. """if ax isNone: fig, ax = plt.subplots(figsize=(10, 6)) cum_returns = (1+ returns).cumprod()if benchmark isnotNone: bench_cum = (1+ benchmark.reindex(cum_returns.index)).cumprod() ax.plot( bench_cum, lw=2, color="grey", alpha=0.6, label=benchmark.name if benchmark.name else"Benchmark", )if live_start_date isnotNone: live_start_date = pd.to_datetime(live_start_date).tz_localize(cum_returns.index.tz) is_mask = cum_returns.index < live_start_date oos_mask = cum_returns.index >= live_start_date ax.plot(cum_returns[is_mask], lw=3, color="forestgreen", label="Backtest") ax.plot(cum_returns[oos_mask], lw=3, color="red", label="Live")else: ax.plot(cum_returns, lw=3, color="forestgreen", label="Strategy") ax.set_yscale("log"if logy else"linear")# Custom percentage formatterdef percentage_formatter(x, pos):if x ==1.0:return"0%"elif x <1.0:returnf"-{(1-x)*100:.0f}%"if (1-x)*100>=1elsef"-{(1-x)*100:.1f}%"else:returnf"+{(x-1)*100:.0f}%"if (x-1)*100>=1elsef"+{(x-1)*100:.1f}%" ax.yaxis.set_major_formatter(ticker.FuncFormatter(percentage_formatter))# Force matplotlib to show more ticks by setting the locatorifnot logy: ax.yaxis.set_major_locator(ticker.MaxNLocator(nbins=8)) ax.set_ylabel("Cumulative returns") ax.set_xlabel("") ax.legend(frameon=True) ax.grid(alpha=0.3)return ax
The visualization above shows the cumulative returns of the rolling max-Sharpe strategy compared to the benchmark. However, there are several practical gaps and limitations to consider:
Universe bias – We selected 12 tickers that survive the whole 10-year span. That removes delisted firms and understates real-world failure risk.
Transaction costs & slippage – Even at monthly turnover they can materially reduce the Sharpe ratio. The back-test currently assumes zero costs, which is not realistic.
Parameter robustness – We fix one look-back length (36 months). A robustness grid (e.g., 24–60 m) or a nested cross-validation loop would reveal sensitivity.