Hide Code
library(tidyverse)
library(rlang)Cookies
This site uses cookies for essential functionality and anonymized analytics. Accept or manage preferences below.
In this post, we will cover some useful applications of R’s subsetting operations. The content of this post is gleaned from Hadley Wickham’s Advance R. This book is aimed at helping R users improve their programming skills beyond day-to-day data analysis.
The following packages are required:
library(tidyverse)
library(rlang)The function match() returns a vector that contains the position indices of the (first) matches of its first argument “x =” in its second “table =”. For instance, match(x, table) will return the position where each element in “x” is found in “table.” This function allows us to create look-up tables. For instance, say we observe a vector of student grades in the world and a table that describe their properties. Let us say our goal is to create a data frame where each row is an observation of student grade and each column is a property associated with that letter grade. We can use a look-up table to map the properties to our vector of grades:
# Grades
grades <- c(1, 2, 2, 3, 1)
# Info
info <- data.frame(
grade = 3:1,
desc = c("Excellent", "Good", "Poor"),
fail = c(F, F, T)
)
info grade desc fail
1 3 Excellent FALSE
2 2 Good FALSE
3 1 Poor TRUE# Match the grades to the "grade" column in the info table
# This is a vector indices we would later use to subset the info table
id <- match(x = grades, table = info[["grade"]])
id[1] 3 2 2 1 3# Subset the info table as a matrix
# Select rows according to the order in which they appear in the index vector
info[id, ] grade desc fail
3 1 Poor TRUE
2 2 Good FALSE
2.1 2 Good FALSE
1 3 Excellent FALSE
3.1 1 Poor TRUEHere, we’ve selected the rows in the info table, sometimes more than once, so that each row is an observation of student grade.
If we would like to randomly sample or bootstrap a vector or a data frame, we can use sample() to generate a random index vector. A shortcut of the sample() function: If the argument x has length 1, is a numeric vector (in the sense of is.numeric()), and is >= 1, then sampling via sample() will only return random vales from the sequence 1 to x.
# Create data frame
df <- data.frame(x = c(1, 2, 3, 1, 2), y = 5:1, z = letters[1:5])
df x y z
1 1 5 a
2 2 4 b
3 3 3 c
4 1 2 d
5 2 1 e# Randomly reorder the rows
# Select the rows in the order they appear in the random vector created by sample()
df[sample(x = nrow(df)), ] x y z
2 2 4 b
3 3 3 c
1 1 5 a
4 1 2 d
5 2 1 e# Select three random rows in the order they appear in the random vector
df[sample(x = nrow(df), size = 3), ] x y z
1 1 5 a
4 1 2 d
2 2 4 b# Select 8 bootstrap replicates
# Notice that replace = TRUE, which indicates that some rows will be selected more than once
df[sample(x = nrow(df), size = 8, replace = TRUE), ] x y z
2 2 4 b
5 2 1 e
4 1 2 d
1 1 5 a
5.1 2 1 e
1.1 1 5 a
3 3 3 c
5.2 2 1 eIn this example, we utilize the sample() function to generate a random index vector, which we then use to subset the data frame. We can easily automate this bootstrapping process by writing our own function:
# Bootstrap data frame
boots_df <- function(df, n, replicate) {
# Create n index vectors
# This returns a list of random index vectors each with size = replicate
list_of_indices <- map(
.x = 1:n,
.f = ~ sample(
x = 1:nrow(df),
size = replicate,
replace = TRUE
)
)
# Pre-allocate list container
list_of_bootstrapped_df <- vector(mode = "list", length = n)
# Loop
for (i in seq_along(1:n)) {
# Select bootstrapped "rows" from the data frame
list_of_bootstrapped_df[[i]] <- df[list_of_indices[[i]], ]
}
# Output is a list of "n" bootstrapped data frames, each with nrow = replicate
list_of_bootstrapped_df
}Let’s see it in action. Suppose we wish to produce 8 bootstrap replicates of the rows of a data frame, and we wish to do this 4 times. Using our function above, we see that the arguments are as follows:
n = 4
replicate = 8
str(boots_df(df = df, n = 4, replicate = 8))List of 4
$ :'data.frame': 8 obs. of 3 variables:
..$ x: num [1:8] 3 1 2 2 3 1 1 2
..$ y: int [1:8] 3 2 1 4 3 5 5 1
..$ z: chr [1:8] "c" "d" "e" "b" ...
$ :'data.frame': 8 obs. of 3 variables:
..$ x: num [1:8] 3 2 2 1 2 1 1 2
..$ y: int [1:8] 3 1 1 5 1 5 5 1
..$ z: chr [1:8] "c" "e" "e" "a" ...
$ :'data.frame': 8 obs. of 3 variables:
..$ x: num [1:8] 1 2 1 1 2 2 1 1
..$ y: int [1:8] 2 4 5 2 1 1 2 5
..$ z: chr [1:8] "d" "b" "a" "d" ...
$ :'data.frame': 8 obs. of 3 variables:
..$ x: num [1:8] 3 2 2 2 1 2 1 2
..$ y: int [1:8] 3 4 1 1 5 4 2 1
..$ z: chr [1:8] "c" "b" "e" "e" ...As can be seen, we have a list of 4 data frames each with 8 rows of bootstrapped replicates. This function can be easily scaled to generate more bootstrap samples and more replicates per sample.
The function order() takes a vector as its input and returns an integer vector describing how to order the subsetted vector. The values in the returned integer vector are “pull” indices; that is, each order(x)[i] tells the position that each x[i] is in the “un-ordered” vector.
# Create a character vector that is out of order
x <- c("b", "c", "a")
x[1] "b" "c" "a"# Find the position of each alphabet in "x" and order them
order(x)[1] 3 1 2# Now select the elements from "x" in the order in which they appear in order(x)
x[order(x)][1] "a" "b" "c"To break ties, you can supply additional variables to order(). You can also change the order from ascending to descending by using decreasing = TRUE. By default, any missing values will be put at the end of the vector; however, you can remove them with na.last = NA or put them at the front with na.last = FALSE.
# Create "un-ordered" vector
set.seed(7)
y <- sample(x = 1:8, replace = TRUE)
y[1] 2 3 7 4 7 2 7 2# Find the position of each number in "x" and order them
order(y)[1] 1 6 8 2 4 3 5 7# According to order(y)
# Select the elements from y in this order:
y[order(y)][1] 2 2 2 3 4 7 7 7For two or more dimensional objects, order() and integer subsetting makes it easy to order either the rows or columns of an object:
# Randomly reorder the rows
# Select columns 3, 2, and 1 in that order
df2 <- df[sample(x = 1:nrow(df)), 3:1]
df2 z y x
3 c 3 3
4 d 2 1
2 b 4 2
1 a 5 1
5 e 1 2# Order the values in column "x"
order(df2[["x"]])[1] 2 4 3 5 1# Order the rows by column x in ascension
# Select the rows based on the positions in order()
# Now the "x" column is ascending
df2[order(df2[["x"]]), ] z y x
4 d 2 1
1 a 5 1
2 b 4 2
5 e 1 2
3 c 3 3# Order the columns based on the alphabetical order of their names
df2[, order(names(df2))] x y z
3 3 3 c
4 1 2 d
2 2 4 b
1 1 5 a
5 2 1 eWe could have sorted vectors directly with sort(), or dplyr::arrange():
# Using arrange() to order based on the "x" column
# The default order of arrangement is ascending
# This is equivalent to SQL's ORDER BY
arrange(.data = df2, df2[["x"]]) z y x
1 d 2 1
2 a 5 1
3 b 4 2
4 e 1 2
5 c 3 3The function arrange() orders the rows of a data frame by the values of selected columns. Unlike other dplyr verbs, arrange() largely ignores grouping; you need to explicitly mention grouping variables (or use .by_group = TRUE) in order to group by them.
First, we need to be familiar with the function rep(x = x, times = y), which repeats x[i] y[i] times. Let’s see it in action:
# Repeat each x[i] y[i] times
rep(x = c(2, 3, 4), times = c(2, 6, 5)) [1] 2 2 3 3 3 3 3 3 4 4 4 4 4# Repeat the vector object x 3 times
rep(x = c(2, 3, 4), times = 3)[1] 2 3 4 2 3 4 2 3 4# Repeat each x[i] 3 times
rep(x = c(2, 3, 4), each = 3)[1] 2 2 2 3 3 3 4 4 4Sometimes you get a data frame where identical rows have been collapsed into one and a count column “n” has been added. rep() and integer subsetting make it easy to ““un-collapse”“, because we can take advantage of rep()s vectorization.
# Create a data frame
df <- data.frame(x = c(2, 4, 1), y = c(9, 11, 6), n = c(3, 5, 1))
df x y n
1 2 9 3
2 4 11 5
3 1 6 1# The first row has count = 3, so repeat it 3 times
# The second row has count = 5, so repeat it 5 times
# The third row has count = 1, so do not repeat
rep(x = 1:nrow(df), times = df$n)[1] 1 1 1 2 2 2 2 2 3# Select the rows in the order they appear in the rep() function
df[rep(x = 1:nrow(df), times = df$n), ] x y n
1 2 9 3
1.1 2 9 3
1.2 2 9 3
2 4 11 5
2.1 4 11 5
2.2 4 11 5
2.3 4 11 5
2.4 4 11 5
3 1 6 1There are two ways to remove columns from a data frame. You can set individual columns to NULL:
# Data frame
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])
df x y z
1 1 3 a
2 2 2 b
3 3 1 c# Remove column z
df$z <- NULLOr you can subset to return only the columns you want:
# Data frame
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])
# Keep only columns x and y
df[c("x", "y")] x y
1 1 3
2 2 2
3 3 1If you only know the columns you don’t want, use set operations to work out which columns to keep. For instance, the function setdiff(x, y, ...)— x is the full set and y is a subset x. The function setdiff() returns the difference between x and y; that is, it returns those elements that are not in the subset y but in the full set “x”.
# Full set
names(df)[1] "x" "y" "z"# Exclude x
setdiff(x = names(df), y = "x")[1] "y" "z"# Exclude x and z
setdiff(x = names(df), y = c("x", "z"))[1] "y"# Select every column except for z
df[setdiff(names(df), "z")] x y
1 1 3
2 2 2
3 3 1Other useful set operations are:
intersect(x, y, …)
union(x, y, …)
setdiff(x, y, …)
setequal(x, y, …)
Read the documentations to learn more about them.
In addition, set operations can be useful in our day-to-day use. We very often need to rm() objects from the global environment that we do need anymore. It sometimes happens that there are many objects in our environment pane, and we only wish to keep a few of them. One way to do so is to list all the objects we wish to remove by name:
# Remove object we do not need
rm(list = c("object1", "object2", ...))However, this can be inefficient since we need to 1) figure out which objects we’d like to remove by calling ls() and 2) type all of them using c(). This can be too much typing and therefore very time-consuming. Alternatively, we can use setdiff() to keep only the objects that we would need:
# Keep only objects that we meed
rm(list = setdiff(x = ls(), y = "object_to_be_kept_1", "object_to_be_kept_2", ...))The function which() gives the TRUE indices of a logical object; that is, their positions in a logical vector. Use which.min() and which.max() for the index of the minimum or maximum.
# Create a named logical vector
x <- sample(x = 1:10, replace = FALSE) < 4
names(x) <- letters[1:10]
# Convert Boolean representation to an integer representation
# Easy to see the positions of the first and last TRUE's
which(x)b d g
2 4 7 # A function that reverses which()
unwhich <- function(x, n) {
# Create a vector of all FALSE with length equal to x
out <- rep_len(x = FALSE, length.out = n)
# Select elements in "out" and convert them to TRUE
# Since "x" is a logical index, the only elements in "out"
# that will be selected are the TRUE values in "x"
out[x] <- TRUE
# Now "out" should be identical to "x" in terms of TRUE and FALSE
out
}
# Reverse x from integer to Boolean
unwhich(x = x, n = 10) [1] FALSE TRUE FALSE TRUE FALSE FALSE TRUE FALSE FALSE FALSERead the documentation to learn more about which().
Create two logical vectors and their integer equivalents. Note: %% indicates x mod y (“x modulo y”). The result of the %% operator is the REMAINDER of a division, Eg. 75 %% 4 = 18 Remainder 3. If the dividend is lower than the divisor, then R returns the same dividend value: Eg. 4 %% 75 = 4.
# Example 1
1:10 %% 2 [1] 1 0 1 0 1 0 1 0 1 0# Logical 1
x1 <- 1:10 %% 2 == 0
x1 [1] FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE# Integer equivalent
x2 <- which(x = x1)
x2[1] 2 4 6 8 10# Logical 2
y1 <- 1:10 %% 5 == 0
y1 [1] FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE TRUE# Integer equivalent
y2 <- which(x = y1)
y2[1] 5 10# X & Y <-> intersect(x, y)
# Logical
x1 & y1 [1] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE TRUE# Integer
intersect(x2, y2)[1] 10# X | Y <-> union(x, y)
# Logical
x1 | y1 [1] FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE TRUE# Integer
union(x2, y2)[1] 2 4 6 8 10 5# X & !Y <-> setdiff(x, y)
# Logical
x1 & !y1 [1] FALSE TRUE FALSE TRUE FALSE TRUE FALSE TRUE FALSE FALSE# Integer
setdiff(x2, y2)[1] 2 4 6 8xor() indicates element-wise exclusive OR.# Import image
knitr::include_graphics("exclusive_or.png")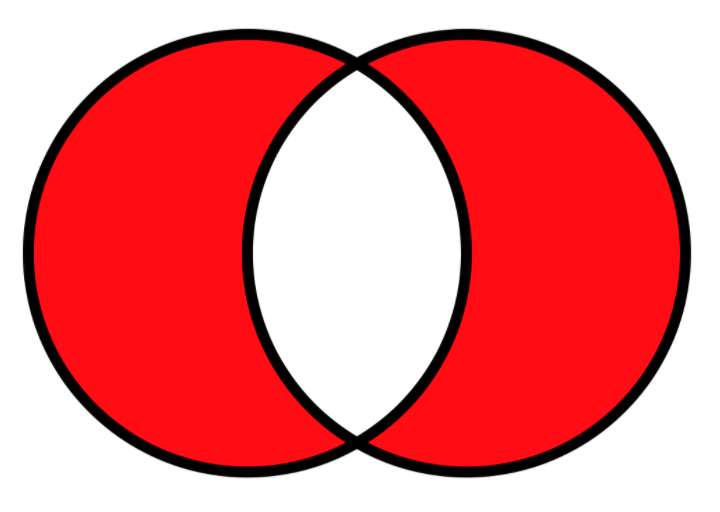
# xor(X, Y) <-> setdiff(union(x, y), intersect(x, y))
# Logical
xor(x1, y1) [1] FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE FALSE FALSE# Integer
setdiff(union(x2, y2), intersect(x2, y2))[1] 2 4 6 8 5# Randomly permute the columns and rows of a data frame
mtcars[
sample(x = 1:nrow(mtcars), replace = FALSE),
colnames(mtcars)[sample(x = 1:length(colnames(mtcars)))]
] qsec cyl hp wt disp am mpg carb gear vs drat
Datsun 710 18.61 4 93 2.320 108.0 1 22.8 1 4 1 3.85
Merc 450SL 17.60 8 180 3.730 275.8 0 17.3 3 3 0 3.07
Toyota Corona 20.01 4 97 2.465 120.1 0 21.5 1 3 1 3.70
Camaro Z28 15.41 8 245 3.840 350.0 0 13.3 4 3 0 3.73
Merc 230 22.90 4 95 3.150 140.8 0 22.8 2 4 1 3.92
Ferrari Dino 15.50 6 175 2.770 145.0 1 19.7 6 5 0 3.62
Dodge Challenger 16.87 8 150 3.520 318.0 0 15.5 2 3 0 2.76
Merc 240D 20.00 4 62 3.190 146.7 0 24.4 2 4 1 3.69
Maserati Bora 14.60 8 335 3.570 301.0 1 15.0 8 5 0 3.54
Cadillac Fleetwood 17.98 8 205 5.250 472.0 0 10.4 4 3 0 2.93
Lotus Europa 16.90 4 113 1.513 95.1 1 30.4 2 5 1 3.77
Mazda RX4 Wag 17.02 6 110 2.875 160.0 1 21.0 4 4 0 3.90
Merc 450SE 17.40 8 180 4.070 275.8 0 16.4 3 3 0 3.07
Pontiac Firebird 17.05 8 175 3.845 400.0 0 19.2 2 3 0 3.08
Merc 280 18.30 6 123 3.440 167.6 0 19.2 4 4 1 3.92
Merc 450SLC 18.00 8 180 3.780 275.8 0 15.2 3 3 0 3.07
Fiat 128 19.47 4 66 2.200 78.7 1 32.4 1 4 1 4.08
Honda Civic 18.52 4 52 1.615 75.7 1 30.4 2 4 1 4.93
Merc 280C 18.90 6 123 3.440 167.6 0 17.8 4 4 1 3.92
Porsche 914-2 16.70 4 91 2.140 120.3 1 26.0 2 5 0 4.43
Duster 360 15.84 8 245 3.570 360.0 0 14.3 4 3 0 3.21
Hornet Sportabout 17.02 8 175 3.440 360.0 0 18.7 2 3 0 3.15
Valiant 20.22 6 105 3.460 225.0 0 18.1 1 3 1 2.76
Volvo 142E 18.60 4 109 2.780 121.0 1 21.4 2 4 1 4.11
Chrysler Imperial 17.42 8 230 5.345 440.0 0 14.7 4 3 0 3.23
Mazda RX4 16.46 6 110 2.620 160.0 1 21.0 4 4 0 3.90
Lincoln Continental 17.82 8 215 5.424 460.0 0 10.4 4 3 0 3.00
Hornet 4 Drive 19.44 6 110 3.215 258.0 0 21.4 1 3 1 3.08
AMC Javelin 17.30 8 150 3.435 304.0 0 15.2 2 3 0 3.15
Ford Pantera L 14.50 8 264 3.170 351.0 1 15.8 4 5 0 4.22
Fiat X1-9 18.90 4 66 1.935 79.0 1 27.3 1 4 1 4.08
Toyota Corolla 19.90 4 65 1.835 71.1 1 33.9 1 4 1 4.22# Second way using ncol() instead of colnames()
# Integer subsetting instead of character
mtcars[sample(x = nrow(mtcars)), sample(x = ncol(mtcars))] wt gear vs qsec mpg am hp cyl carb disp drat
Merc 450SE 4.070 3 0 17.40 16.4 0 180 8 3 275.8 3.07
AMC Javelin 3.435 3 0 17.30 15.2 0 150 8 2 304.0 3.15
Lotus Europa 1.513 5 1 16.90 30.4 1 113 4 2 95.1 3.77
Maserati Bora 3.570 5 0 14.60 15.0 1 335 8 8 301.0 3.54
Fiat 128 2.200 4 1 19.47 32.4 1 66 4 1 78.7 4.08
Mazda RX4 2.620 4 0 16.46 21.0 1 110 6 4 160.0 3.90
Chrysler Imperial 5.345 3 0 17.42 14.7 0 230 8 4 440.0 3.23
Porsche 914-2 2.140 5 0 16.70 26.0 1 91 4 2 120.3 4.43
Volvo 142E 2.780 4 1 18.60 21.4 1 109 4 2 121.0 4.11
Merc 280C 3.440 4 1 18.90 17.8 0 123 6 4 167.6 3.92
Lincoln Continental 5.424 3 0 17.82 10.4 0 215 8 4 460.0 3.00
Mazda RX4 Wag 2.875 4 0 17.02 21.0 1 110 6 4 160.0 3.90
Merc 230 3.150 4 1 22.90 22.8 0 95 4 2 140.8 3.92
Fiat X1-9 1.935 4 1 18.90 27.3 1 66 4 1 79.0 4.08
Merc 240D 3.190 4 1 20.00 24.4 0 62 4 2 146.7 3.69
Toyota Corolla 1.835 4 1 19.90 33.9 1 65 4 1 71.1 4.22
Ford Pantera L 3.170 5 0 14.50 15.8 1 264 8 4 351.0 4.22
Honda Civic 1.615 4 1 18.52 30.4 1 52 4 2 75.7 4.93
Valiant 3.460 3 1 20.22 18.1 0 105 6 1 225.0 2.76
Hornet 4 Drive 3.215 3 1 19.44 21.4 0 110 6 1 258.0 3.08
Dodge Challenger 3.520 3 0 16.87 15.5 0 150 8 2 318.0 2.76
Ferrari Dino 2.770 5 0 15.50 19.7 1 175 6 6 145.0 3.62
Merc 450SL 3.730 3 0 17.60 17.3 0 180 8 3 275.8 3.07
Merc 450SLC 3.780 3 0 18.00 15.2 0 180 8 3 275.8 3.07
Camaro Z28 3.840 3 0 15.41 13.3 0 245 8 4 350.0 3.73
Pontiac Firebird 3.845 3 0 17.05 19.2 0 175 8 2 400.0 3.08
Toyota Corona 2.465 3 1 20.01 21.5 0 97 4 1 120.1 3.70
Datsun 710 2.320 4 1 18.61 22.8 1 93 4 1 108.0 3.85
Cadillac Fleetwood 5.250 3 0 17.98 10.4 0 205 8 4 472.0 2.93
Duster 360 3.570 3 0 15.84 14.3 0 245 8 4 360.0 3.21
Hornet Sportabout 3.440 3 0 17.02 18.7 0 175 8 2 360.0 3.15
Merc 280 3.440 4 1 18.30 19.2 0 123 6 4 167.6 3.92# A function that randomly selects m rows from a data frame
select_m_rows <- function(data, m) {
# Warning
if (m > nrow(data)) {
abort("Not enough rows in data frame")
}
# Select rows randomly and include all columns
data[sample(x = 1:nrow(data), size = m), , drop = FALSE]
}Let’s see it in action using the iris data set:
select_m_rows(data = iris, m = 10) Sepal.Length Sepal.Width Petal.Length Petal.Width Species
149 6.2 3.4 5.4 2.3 virginica
87 6.7 3.1 4.7 1.5 versicolor
116 6.4 3.2 5.3 2.3 virginica
82 5.5 2.4 3.7 1.0 versicolor
8 5.0 3.4 1.5 0.2 setosa
81 5.5 2.4 3.8 1.1 versicolor
112 6.4 2.7 5.3 1.9 virginica
79 6.0 2.9 4.5 1.5 versicolor
43 4.4 3.2 1.3 0.2 setosa
75 6.4 2.9 4.3 1.3 versicolorWhat if we need the first and last rows selected, but everything in between can be random?
# Extend the function to ensure that the first and last rows are selected
# Everything in between are random
select_m_rows_extended <- function(data, m) {
# Warning
if (m > nrow(data)) {
abort("Not enough rows in data frame")
}
# Select first row and last row
# "Sandwich" the sample() vector in between
data[
c(
1,
sample(x = 2:(nrow(data) - 1), size = (m - 2)),
nrow(data)
), ,
drop = FALSE
]
}Let’s see it in action using the mtcars data set:
select_m_rows_extended(data = mtcars, m = 10) mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160.0 110 3.90 2.620 16.46 0 1 4 4
Merc 450SLC 15.2 8 275.8 180 3.07 3.780 18.00 0 0 3 3
Porsche 914-2 26.0 4 120.3 91 4.43 2.140 16.70 0 1 5 2
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3
Datsun 710 22.8 4 108.0 93 3.85 2.320 18.61 1 1 4 1
Toyota Corona 21.5 4 120.1 97 3.70 2.465 20.01 1 0 3 1
Mazda RX4 Wag 21.0 6 160.0 110 3.90 2.875 17.02 0 1 4 4
AMC Javelin 15.2 8 304.0 150 3.15 3.435 17.30 0 0 3 2
Maserati Bora 15.0 8 301.0 335 3.54 3.570 14.60 0 1 5 8
Volvo 142E 21.4 4 121.0 109 4.11 2.780 18.60 1 1 4 2Finally, what if we wish to randomly select a blocked sample, i.e., the rows have to be contiguous (an initial row, a final row, and everything in between)?
# Successive lines together as a blocked sample
m <- 10
# The starting row cannot be less than m rows from the last row of the data
# Or else there wound not be enough rows to select m successive rows from
start <- sample(x = 1:(nrow(mtcars) - m + 1), size = 1)
# The ending row must be m rows from the starting row
end <- start + m - 1
# Select the consecutive rows between random starting row
mtcars[start:end, , drop = FALSE] mpg cyl disp hp drat wt qsec vs am gear carb
Hornet 4 Drive 21.4 6 258.0 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360.0 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225.0 105 2.76 3.460 20.22 1 0 3 1
Duster 360 14.3 8 360.0 245 3.21 3.570 15.84 0 0 3 4
Merc 240D 24.4 4 146.7 62 3.69 3.190 20.00 1 0 4 2
Merc 230 22.8 4 140.8 95 3.92 3.150 22.90 1 0 4 2
Merc 280 19.2 6 167.6 123 3.92 3.440 18.30 1 0 4 4
Merc 280C 17.8 6 167.6 123 3.92 3.440 18.90 1 0 4 4
Merc 450SE 16.4 8 275.8 180 3.07 4.070 17.40 0 0 3 3
Merc 450SL 17.3 8 275.8 180 3.07 3.730 17.60 0 0 3 3This can easily be done using R’s subsetting operators:
# A function that orders the columns of data frame alphabetically
order_columns <- function(data) {
# Select columns according to the indices generated by order()
# We could also use sort()
data[, order(x = names(data))]
}
# Test
as_tibble(order_columns(data = mtcars))# A tibble: 32 × 11
am carb cyl disp drat gear hp mpg qsec vs wt
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1 4 6 160 3.9 4 110 21 16.5 0 2.62
2 1 4 6 160 3.9 4 110 21 17.0 0 2.88
3 1 1 4 108 3.85 4 93 22.8 18.6 1 2.32
4 0 1 6 258 3.08 3 110 21.4 19.4 1 3.22
5 0 2 8 360 3.15 3 175 18.7 17.0 0 3.44
6 0 1 6 225 2.76 3 105 18.1 20.2 1 3.46
7 0 4 8 360 3.21 3 245 14.3 15.8 0 3.57
8 0 2 4 147. 3.69 4 62 24.4 20 1 3.19
9 0 2 4 141. 3.92 4 95 22.8 22.9 1 3.15
10 0 4 6 168. 3.92 4 123 19.2 18.3 1 3.44
# ℹ 22 more rowsas_tibble(order_columns(data = iris))# A tibble: 150 × 5
Petal.Length Petal.Width Sepal.Length Sepal.Width Species
<dbl> <dbl> <dbl> <dbl> <fct>
1 1.4 0.2 5.1 3.5 setosa
2 1.4 0.2 4.9 3 setosa
3 1.3 0.2 4.7 3.2 setosa
4 1.5 0.2 4.6 3.1 setosa
5 1.4 0.2 5 3.6 setosa
6 1.7 0.4 5.4 3.9 setosa
7 1.4 0.3 4.6 3.4 setosa
8 1.5 0.2 5 3.4 setosa
9 1.4 0.2 4.4 2.9 setosa
10 1.5 0.1 4.9 3.1 setosa
# ℹ 140 more rowsas_tibble(order_columns(data = USArrests))# A tibble: 50 × 4
Assault Murder Rape UrbanPop
<int> <dbl> <dbl> <int>
1 236 13.2 21.2 58
2 263 10 44.5 48
3 294 8.1 31 80
4 190 8.8 19.5 50
5 276 9 40.6 91
6 204 7.9 38.7 78
7 110 3.3 11.1 77
8 238 5.9 15.8 72
9 335 15.4 31.9 80
10 211 17.4 25.8 60
# ℹ 40 more rowsThat is it with R’s subsetting operators. Combined with other data wrangling tools from the tidyverse packages, R’s subsetting operations can be powerful as far as data analysis tasks are concerned. Next up in R programming, I will write about the the tidyverse’s functional programming tool— purrr— which I have been using here and there in many of my posts. Having an understanding of R functionals have helped me tremendously in my day-to-day use of R, and so I look forward to documenting my learning process via a post.